- AI
- A
Algebra of Justice: How Engineers Digitized Courts 50 Years Before AI
Currently, Legal AI is dominated by a rather naive idea: if a large language model can already write decent legal text, then all that's left is to give it a corpus of court rulings, add a chat, and get a digital lawyer
The problem is that a court is not a textual genre. A court is a system.
And as soon as you move beyond tasks like "summarize the ruling," "extract norms," or "draft a petition," an unpleasant truth emerges: LLMs work fairly well as an interface but are poorly suited to the role of the architecture itself. They can explain things beautifully. But they do a poor job replacing a procedural model, a probabilistic engine, a routing layer, or constraint checking.
This is especially noticeable in judicial analytics tasks: where a case may get stuck, at which stage the trajectory breaks, where the process branches, where a calculation is needed rather than text. And here it suddenly turns out that the most useful ideas are not in the latest AI marketing, but in works from half a century ago.
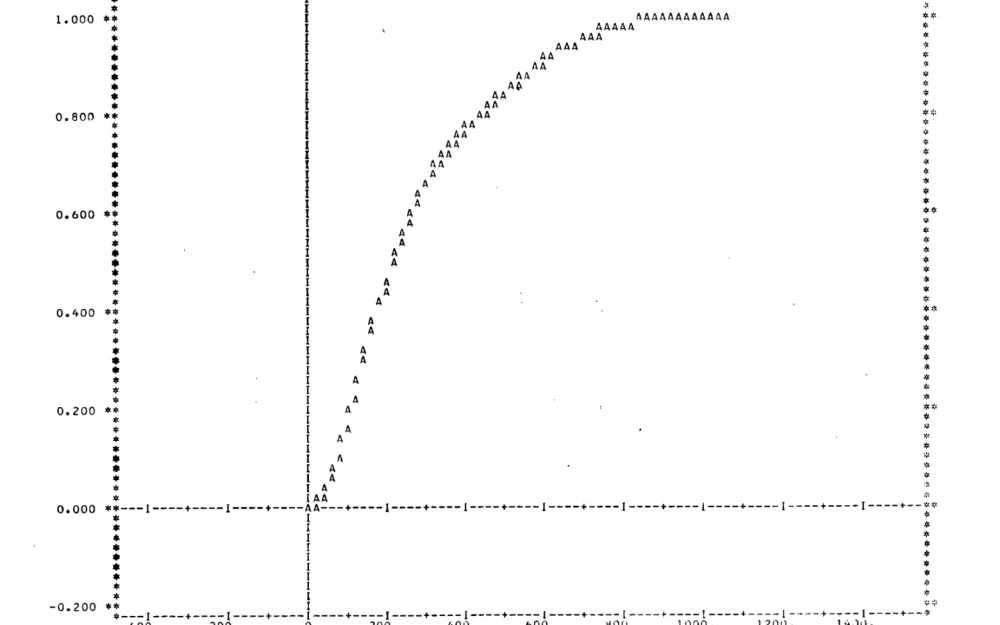
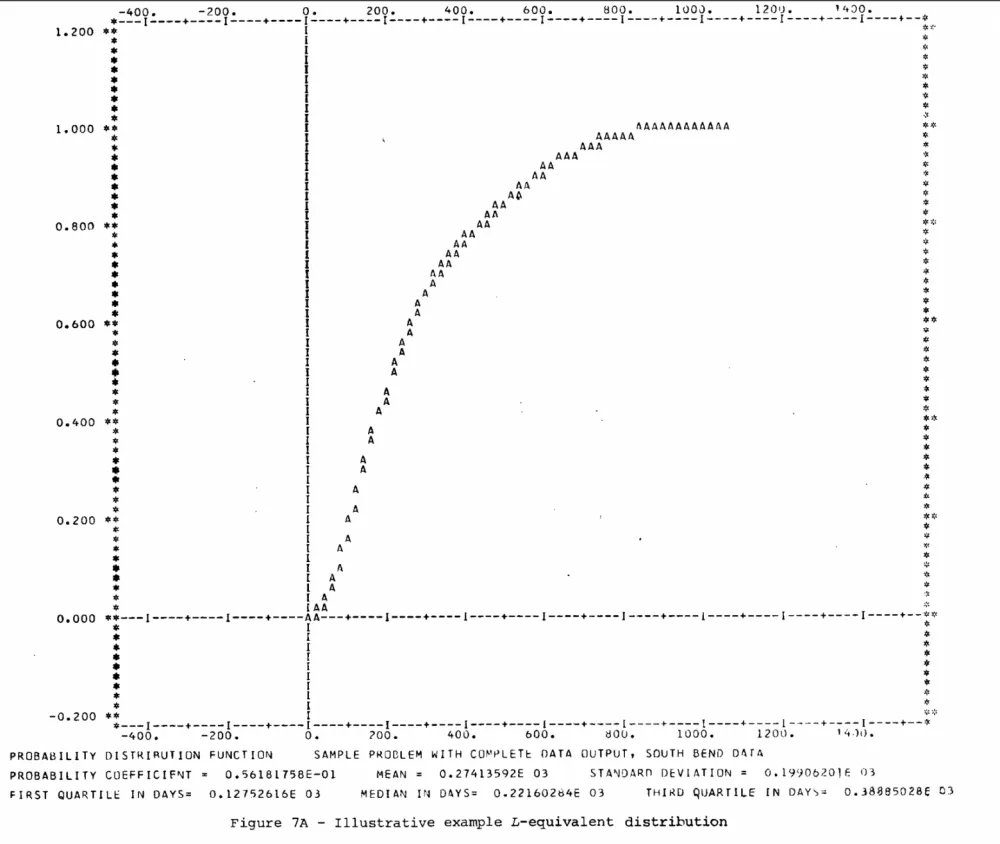
As early as the late 1960s, researchers modeled the passage of felony defendants through the court system of the District of Columbia, and by 1973 they were already describing a primarily algebraic approach to simulating legal systems for joint work between engineers and lawyers, including using data from Indiana courts. From an engineering perspective, this is important not as a historical curiosity, but as an early attempt to honestly answer the question: what exactly are we automating in law – the text, the decision, or the system itself.
Below are a few simple but, it seems, important ideas from reading two half-century-old papers – Simulation Applied to a Court System (Jean G. Taylor, Joseph A. Navarro, Robert H. Cohen, 1968) and An algebraic method for simulating legal systems (Michael K. Sain, Eugene W. Henry, John J. Uhran, 1973).
Why the LLM wrapper quickly hits a ceiling
When we talk about "automating a lawyer," we almost always substitute the task. We think we need to model the thinking of an experienced specialist: how they read a case, how they notice weaknesses, how they assess prospects. But in practice, this often leads to the model imitating the style of reasoning better than the structure of the process itself.
For a contract, this is still tolerable. For the court – no longer.
Because in the judicial task, there are at least five different entities that sometimes get lumped together:
Text.
Procedural trajectory.
Restrictions and deadlines.
Probabilistic transitions between stages.
Explaining the result to a person.
LLM is mostly suitable for the fifth point and partially for the first. Everything else it can only mask. And this is exactly where old court simulations turn out to be unexpectedly modern.
Lesson one: first the model of the process, then the "smart lawyer"
Early court simulations were built around a very down-to-earth idea: the court should be seen as a system for processing case flows, not as the magic of individual participants. This sounds boring, but this is where engineering honesty lies.
GPSS, used in early models of this kind, was originally created as a General Purpose Simulation System for discrete processes, where key roles are played by events, queues, resources, and transitions between states. And this is almost the perfect metaphor for the court: case filing, distribution, waiting, petition, transfer, next instance, exit.
From here, a very simple but painful conclusion for Legal AI: before making the model "think like a judge," you need to at least describe what exactly happens with a case in the system. The prompt is not more important than the process graph. The subtleness of the formulation is not more important than the topology.
This is why bad Legal AI usually looks like this: one big LLM call where the case narrative, documents, a couple of judicial acts, and the request "evaluate the chances" are thrown together. And a good one – like a conveyor belt, where the language model doesn’t touch anything that can be described by rules, a graph, or statistics.
Lesson two: law is nonlinear, and this is not a bug, but a fundamental property of the system
Lawyers already know this in practice, but developers somehow regularly forget about it. A court case almost never goes in a straight line. There are returns. There are transfers. There are appeals. There is new evidence. There are procedural loops after which the case seems "the same," but in a different configuration.
That’s why the work from 1973 still resonates: its authors described primarily algebraic technique for simulating social systems within the logic of system theory and were clearly thinking in terms of transitions' structure, not texts. For a developer, this is an important signal: it’s more convenient to think of a legal process as a state graph with probabilistic transitions rather than as a chain of paragraphs.
By the way, this leads to one unpleasant truth about many modern AI products in law. They try to solve a workflow engine problem using a chat completion API. That is, instead of modeling the system, they take a model that is good at continuing text and ask it to be a proceduralist, analyst, router, and probability calculator all at once.
Does it work on beautiful demos? Yes.
Does it break on a real, messy outline? Also yes.
Lesson three: a lawyer doesn't need an "answer", but a map of how they got to that answer
The most dangerous mistake in Legal AI is thinking that the user just needs the final prediction. In reality, what they need is a structure of trust. It’s not enough for a lawyer to hear: “the probability of the lawsuit’s success is 63%.” A judge needs even more. They need to understand what factors influenced the conclusion, where the model is confident, where it’s not, what was taken from the data, what is an interpretation, and where errors are even possible at all.
In modern discussions of predictive justice, this issue constantly resurfaces: judicial decisions are indeed becoming raw material for models, but explainability and verifiability of conclusions remain one of the central challenges. Therefore, explainable AI in law is not a decorative layer, but an attempt to make the system professionally viable: so that errors can be detected, disputed, and not just admired for the smoothness of the answer.
From an engineering perspective, this means something simple: the result should not come in the form of a “black box with a confident tone,” but in the form of an interface. Where assumptions are visible. Where the case’s route is visible. Where the factors that played a role are visible. Where the model relies on statistics in some areas and on textual reconstruction in others.
In short: not just an answer, but observability.
How I would design a Legal AI system today
If we discard all the AI magic, the architecture for judicial analytics, as it seems, could look something like this:
Data layer: judicial acts, case cards, procedural documents, metadata.
Normalization layer: entity extraction, stages, events, deadlines, participants.
Process model: case flow graph, allowable transitions, exceptions, loops.
Probabilistic layer: frequencies, calibration, confidence, intervals, not just “yes/no”.
Rules and validation: checks for contradictions, omissions, procedural restrictions.
LLM layer: result explanation, handling user queries, generating understandable text.
UI layer: visualization of routes, factors, scenarios, and areas of uncertainty.
LLM here does not disappear. But it stops being the god of the system. It becomes the translator between the machine model of the process and the human.
And, honestly, this is a much more realistic role. Because LLM is good at interpretation, summarization, classification by context, and working with heterogeneous text. But when it is tasked with being both the engine of the process, the statistical apparatus, and the source of truth, hallucinations begin, which are especially toxic in law.
Text generation, forecasting, explanation, routing, and consistency checks are different tasks. If mixed, the system starts to sound smart, but loses its engineering foundation. If separated, there emerge things without which Legal AI does not mature: reproducibility, debugging, quality measurement, and at least some protection from pretty nonsense.
This, by the way, is the main lesson from those old works. The researchers of the 1960s and 1970s didn’t try to make a “digital judge.” They tried to understand how the process of a case actually works. And perhaps that’s why their approach today seems more modern than many presentations labeled "AI for Law".
Sentencing.
The most expensive mistake in Legal AI is automating the wrong level of the system.
If you model a lawyer, you get a charming interface. If you model the court as a system, there’s a chance to build a working tool. And that is no longer marketing, but architecture.










![From Virtual Hands to AI for Survivalists: Curious Open Agent OSes [and One Hardware Project]](https://cdn.tekkix.com/imgs/2026/05/habrcom/big/ce0b1057616faed51cd8b9f3b2b9.webp)
Write comment