
- Hardware
- A
Rubin + Helios: new GPU platforms from NVIDIA and AMD in January digest
January is usually a sleepy month in the hardware world, but this time everything went off script - two top vendors showcased their flagship products.
Hello everyone! This is Sergey Kovalev, dedicated server manager at Selectel. In this digest, I have gathered the details of the most talked-about hardware novelties for January — from GPUs to new disks and networking equipment. Details below!
GPU
NVIDIA — new generation GPU Rubin™

NVIDIA launches the Vera Rubin™ platform (the next generation after Blackwell Ultra), built on the principle of "extreme codesign" — co-designing hardware and software. The platform is focused on agent AI, MoE models, and long context.
Vera Rubin™ is a full-fledged system platform with six key components:
NVIDIA Vera™ — Arm processor for AI factories (88 cores Olympus, Armv9.2);
Rubin™ GPU — next-generation accelerator with HBM4 and NVLink 6;
NVLink 6 Switch — liquid-cooled switch with 400G SerDes;
ConnectX-9 SuperNIC — network adapter with support for Ethernet Photonics;
BlueField-4 DPU — for processing networking and storage tasks;
Spectrum-6 Ethernet Switch — switch for cluster networks.
The NVIDIA Vera™ processor is one of the key elements of the platform. It is a specialized Arm chip for agent AI workloads and large AI factories.
As I mentioned, it has 88 cores, all of which are custom Armv9.2 Olympus with support for spatial multithreading. The system works with an impressive memory capacity of up to 1.5 TB LPDDR5x, providing a bandwidth of up to 1.2 TB/s. Moreover, the connection to the GPU is realized through the NVLink-C2C interface, which delivers 1.8 TB/s in duplex mode.
NVIDIA specifically emphasizes the energy efficiency of Vera and the built-in support for confidential computing. However, today this is no longer a killer feature.
The Rubin™ GPU is aimed at training and inference of large models with a focus on low precision and hardware adaptive data compression.
Main specifications:
performance: up to 50 petaflops in FP4 for inference (five times more powerful than Blackwell) and up to 35 petaflops for training;
memory: 288 GB HBM4 with a bandwidth of 22 TB/s (exceeds Blackwell by 2.8 times);
interconnect: NVLink 6 bus with a speed of 3.6 TB/s per GPU (twice as fast as Blackwell).
Separately, such Rubin™ GPUs will be presented in the already traditional HGX systems.
In the maximum configuration, the Vera Rubin™ NVL72 platform combines 54 TB LPDDR5x and 20.7 TB HBM4. The aggregated bandwidth of HBM reaches 1.6 PB/s, and the interconnect within the rack is 260 TB/s, which, in NVIDIA's words, exceeds the bandwidth of the entire internet. Such density comes at a power consumption level of 190–230 kW per rack.
Particular attention deserves NVLink 6 — a liquid-cooled switch with 400G SerDes, providing fully connected communication between all GPUs in the rack.
Together with Rubin, NVIDIA also introduced a new inference context memory storage infrastructure — Inference Context Memory Storage Platform.
It is built on BlueField-4 and is designed for sharing and reusing KV cache in agent-based AI workloads. Compared to traditional network storage, this platform provides a fivefold increase in tokens per second, better performance per cost, and higher energy efficiency.
Although NVIDIA announces the start of full-scale production of Rubin, server solutions from partners are expected in the second half of the year. Traditionally, major market players express interest in the top platform in the news.
And to avoid dependence on supply schedules and start working on your projects, you can consider the current flagships. We have just prepared a fleet of machines with the configuration of NVIDIA B300.
AMD Helios™ — rack solution with new AMD Instinct MI455X GPUs

At CES 2026, AMD revealed details about its new rack-scale AI platform Helios, as well as introduced the next-generation accelerators Instinct MI430X, MI440X, and MI455X, which will be part of the MI400-series family. The company positions this lineup as a comprehensive solution set for AI.
Helios is AMD's first rack-scale system for high-performance computing. The platform is built on EPYCTM Zen 6 (Venice) processors and combines up to 72 Instinct MI455X accelerators in its maximum configuration. The total amount of HBM4 memory in the rack reaches 31 TB with an aggregated bandwidth of up to 1.4 PB/s.
According to AMD's calculations, Helios is capable of delivering up to 2.9 exaflops in FP4 for inference and up to 1.4 exaflops in FP8 for training AI models. The company immediately clarifies that the system is designed for modern AI data centers with corresponding power and cooling requirements.
In addition to the flagship MI455X, AMD confirmed the expansion of the entire Instinct MI400X family. The new accelerators will be built on compute chiplets manufactured using TSMC's 2nm process (N2), making the MI400X the first GPUs to utilize this class of lithography. Another significant change is that for the first time, Instinct accelerators will be divided into several subfamilies within a single architecture, as the MI400X will be implemented in different variants of CDNA 5.
Thus, AMD is clearly moving away from the "one accelerator for all scenarios" approach, offering a lineup ranging from individual GPUs with PCIe connectivity to integrated rack solutions like Helios. In 2026, judging by the company's statements, there will be a "suitable" Instinct MI400X for virtually any AI task.
Microsoft Maia 200 — GPU for Inference

Microsoft introduced its own AI accelerator Maia 200, built on a 3nm process and focused exclusively on the inference of large models. This is already the second generation of accelerators in the lineup.
Key specifications of the Maia 200:
3-nm technology process;
custom tensor cores with FP8/FP4 support;
216 GB HBM3e with a bandwidth of up to 7 TB/s;
272 MB SRAM;
over 140 billion transistors;
TDP of 750 W, with a liquid cooling system.
In terms of performance, the Maia 200 demonstrates over ten petaflops in FP4, which is almost half of NVIDIA Blackwell's metrics. In the FP8 format, the accelerator provides over five petaflops, falling short of Blackwell by about two times. Thus, Microsoft is clearly not betting on absolute maximum performance.
At the system level, the Maia 200 uses an unusually simple scaling scheme for modern AI clusters. Instead of proprietary interconnects, it employs a two-tier unified network fabric based on standard Ethernet. A special transport layer for Maia AI, as well as a closely integrated network adapter, allows operating without proprietary high-speed buses.
In practical scenarios, the Maia 200 will become part of Microsoft's heterogeneous AI infrastructure and will be used to work with various models, including OpenAI's GPT-5.2. The accelerators will be utilized in Microsoft Foundry and Microsoft 365 Copilot, while the Microsoft Superintelligence team plans to use the Maia 200 for generating synthetic data and reinforcement learning, accelerating the preparation and filtering of specialized datasets for next-generation models.
Zhenwu 810E — GPU with 96 GB of HBM2e memory onboard

The T-Head Semiconductor division, part of Alibaba Group, introduced its own AI accelerator Zhenwu 810E.
The chip is positioned as a universal solution for training and inference of AI models, as well as for resource-intensive tasks such as autonomous driving. An important point is that both the hardware and software architectures are developed internally at T-Head without relying on external platforms.
A proprietary interconnect ICN (Inter-Chip Network) is used for scaling. Each chip has seven such interfaces for direct connection to other accelerators, with a total bandwidth reaching 700 GB/s.
Key technical features of the Zhenwu 810E:
proprietary hardware-software architecture T-Head;
96 GB HBM2e memory;
proprietary interconnect ICN;
up to 700 GB/s inter-chip bandwidth;
7 ICN links per chip;
PCIe 5.0 x16 connection interface.
According to reports, the Zhenwu 810E outperforms the NVIDIA A800 accelerator and is capable of competing with the NVIDIA H20. This model is specially adapted for the Chinese market under U.S. export restrictions.
Alibaba is already actively using the Zhenwu 810E to train its own large language models Qianwen, as well as for AI inference in the cloud.
Moreover, based on these accelerators, services are provided to national clients, such as the State Grid Corporation of China (SGCC), the Chinese Academy of Sciences, and the electric vehicle manufacturer Xpeng.
Iluvatar CoreX — NVIDIA "killer" GPU
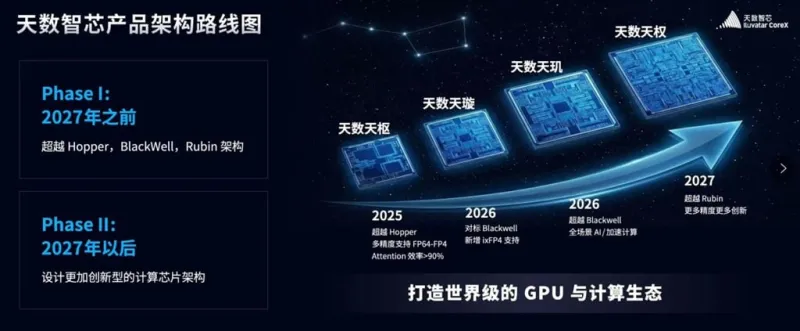
The Chinese startup Iluvatar CoreX, according to DigiTimes, has revealed an ambitious roadmap for the release of AI GPU accelerators aimed at direct competition with NVIDIA's solutions. The company plans to launch four generations of architectures covering the period from now until at least 2027.
The current developments of Iluvatar CoreX are based on an architecture codenamed Tianshu. According to the company, the accelerators based on it already outperform the NVIDIA Hopper generation GPUs, including the H200. These chips are positioned as solutions for training and inference in data centers and are designed for large AI clusters.
The further roadmap looks even more aggressive:
beginning and middle of 2026 Tianxuan — accelerators aimed at competing with NVIDIA Blackwell, including B200;
end of 2026 Tianji — next-generation architecture that, according to Iluvatar CoreX, should outperform Blackwell in performance;
2027 Tianquan — GPUs aimed at surpassing the NVIDIA Rubin™ platform.
After Tianquan, the company plans to shift its focus to developing "breakthrough computing architectures."
In practice, the startup can no longer be called purely experimental. As of June 30, 2025, Iluvatar CoreX has shipped over 52,000 GPUs to approximately 290 corporate clients;
In addition to data center GPUs, Iluvatar CoreX is developing the peripheral computing direction. In this line, the company is developing Tongyang chips intended for edge scenarios. According to the startup, one of these processors — the TY1000 — has outperformed the NVIDIA Jetson AGX Orin in real workloads, including tasks related to computer vision, natural language processing, and AI inference with large language models like DeepSeek 32B.
It’s a very loud and ambitious announcement, but even a major player like AMD has not managed to break NVIDIA's hegemony. The statements from startups with significantly smaller production volumes and limited technologies seem provocative against this backdrop. Let's wish them luck and evaluate their successes in a year.
Deepx — GPU Accelerators in the Form of Expansion Cards

The South Korean startup Deepx introduced three accelerators based on its own Genesis NPU module. The new products — DX-H1 V-NPU, DX-H1 Quattro, and DX-M — were showcased at CES 2026 and are targeted at different scenarios.
The DX-H1 V-NPU model is primarily designed for processing video streams — decoding, encoding, and transcoding while simultaneously performing inference. Deepx claims that compared to GPU solutions, the device allows for an approximately 80% reduction in equipment costs and up to 85% reduction in power consumption at the same channel density.
Key specifications of the DX-H1 V-NPU:
low-profile PCIe 3.0 x16 card (x8 lanes);
two hardware video codecs and two NPUs;
up to 50 TOPS (INT8) for real-time inference;
decoding up to 64 channels of H.264/H.265 (1080p, 30 fps), encoding up to 32 channels of H.264/H.265 (1080p, 30 fps);
memory — 16 GB LPDDR5 for video codecs and 8 GB for NPUs;
HDMI 2.0 interface, 32 GB eMMC storage;
maximum power consumption — 40 W.
The DX-H1 Quattro accelerator is aimed at more versatile AI tasks in data centers and at the edge. Here, the focus is not on video, but on computational density and energy efficiency.
Main parameters of the DX-H1 Quattro:
PCIe 3.0 x16 expansion card;
four NPUs with a total performance of up to 100 TOPS (INT8);
16 GB LPDDR5;
power consumption 20 W.
The most compact solution in the lineup is the DX-M1 M.2 — an AI accelerator for embedded and edge systems:
executed in M.2 2280 format;
performance up to 25 TOPS;
power consumption not exceeding 5 W;
PCIe 3.0 x4 interface;
support for x86 and Arm-based systems.
Deepx clearly bets on a niche where GPUs are excessive in power consumption and price: video analytics, edge AI, and compact server systems. The DX-H1 and DX-M1 lineup appears to be an attempt to occupy an intermediate position between classic CPU servers and systems with "heavy" GPU accelerators.
Drives
Seagate — 32TB HDD

Seagate has released 32TB hard drives in three lines — SkyHawk AI, IronWolf Pro, and Exos. All models are made in LFF form factor, use traditional CMR magnetic recording combined with HAMR, and connect via SATA 6 Gb/s. This is currently the maximum capacity for Seagate's serial HDDs designed for 24/7 operation.
The devices have the following common characteristics:
capacity of 32 TB;
data transfer rate up to 285 MB/s;
spindle speed — 7,200 RPM (for IronWolf Pro and Exos);
hermetic helium chamber;
MTBF up to 2.5 million hours.
SkyHawk AI is aimed at video surveillance systems with analytics. The drive is designed for simultaneous recording of up to 64 HD video streams and processing of up to 32 AI streams. Technologies are used to minimize frame loss during intensive recording and accelerate array recovery after failures.
IronWolf Pro is designed for NAS systems and multi-disk storage. It is a disk with a rated load of up to 550 TB per year. This line also features technology that ensures load balancing, proper RAID operation, and reduced power consumption.
The health of the drive is monitored by IronWolf Health Management, providing proactive monitoring and operational recommendations.
The server line is represented by Seagate Exos — a disk for data centers with continuous load. For random access, it claims up to 170 IOPS for read and 350 IOPS for write (4K, QD16). The disks are optimized for power consumption, which can be important for dense racks and scaling.
For disks with larger capacities, cost per TB is an important metric. According to Seagate, in this regard, the disks can be competitive.
Networking Equipment
Panmnesia Panswitch — chip switch for HPC computing

The South Korean startup Panmnesia demonstrated the Panswitch chip switch (H1SW06245ACFAA), created for HPC platforms in data centers for AI tasks. Along with it, the PanRDK developer board has been introduced, intended for testing and prototyping CXL systems.
The key feature of Panswitch is full support for the CXL 3.2 specification, including Port-based Routing (PBR). According to the company, this is the first solution of its kind, allowing thousands of CXL devices to be combined into a single computing environment.
Main characteristics and features:
full support for CXL 3.2, including Port-based Routing (PBR);
building scalable CXL fabrics connecting thousands of devices;
support for various topologies: tree, mesh, Dragonfly, and other HPC architectures;
proprietary Panmnesia CXL controller with ultra-low latency;
support for PCI Express 6.4 interface;
optimization of data transmission paths for specific AI workloads.
Panmnesia reports that shipments of Panswitch chips and pilot systems have already begun, making the platform available for early adoption and experiments with next-generation CXL fabrics.
MikroTik — switch with two devices housed in one unit

MikroTik has introduced the L3 switch CRS804 DDQ, aimed at small AI and HPC infrastructures.
The device is designed in a half-width 1U form factor, allowing two switches to be placed in one rack unit.
Key features
ASIC: Marvell 98DX7335;
CPU: 4-core Arm Annapurna Labs AL52400 (up to 2 GHz);
memory: 4 GB RAM, 512 MB NAND;
ports: 4 × QSFP56-DD (400 Gbps), 2 × 10GbE RJ45, console port RJ45;
2 hot-swappable PSUs (100–240 V);
power consumption up to 123 W.
The estimated cost of the MikroTik CRS804 DDQ starts at $1,300, making it one of the most affordable devices with 400G ports for entry-level and mid-range AI tasks.
Conclusion
The world of GPU infrastructure is evolving—NVIDIA is setting the pace with the Vera Rubin platform, AMD is responding with the Helios rack solution, and Microsoft is focusing on inference. Chinese players are actively exploring the niche of competitive GPUs. At the same time, the “supporting” infrastructure is also growing: Seagate is launching 32 TB HDDs for AI workloads, and Panmnesia is paving the way for scalable CXL factories.
For customers, this means more choices, flexibility, and possibly reduced costs. And for us, it’s an opportunity to offer clients truly diverse solutions. We continue to keep an eye on hardware innovations, stay with us.


![From Virtual Hands to AI for Survivalists: Curious Open Agent OSes [and One Hardware Project]](https://cdn.tekkix.com/imgs/2026/05/habrcom/big/ce0b1057616faed51cd8b9f3b2b9.webp)



Write comment