
- Security
- A
Case study of code analysis
Greetings to all tekkix readers. If you throw out administrative work, then my main activity at work is finding various vulnerabilities. Most often, my toolkit consists of a set of debuggers, dynamic analyzers, and the like. But sometimes you have to deal with the analysis of source code of arbitrary degrees of curvature of comprehensibility. And this is practically a separate parallel world in the field of security.
This time, fate brought me to the analysis of the OpenJDK source code (you can see it, for example, on GitHub). I started with the basics: got the static code analysis logs and began to study them. In general, the log was quite boring - about 1500 warnings, 99% of which were false positives of the analyzer. The most annoying thing is that even though I know in advance that almost always more than 99% of the warnings are useless, I still have to spend time checking if it falls into that very 1%.
I will still analyze one relatively interesting case. In the best traditions of the PVS-Studio blog, I will first show a piece of code and suggest finding the problem with your eyes.
static boolean setHuffTable(JNIEnv *env,
JHUFF_TBL *huff_ptr,
jobject table) {
jshortArray huffLens;
jshortArray huffValues;
jshort *hlensBody, *hvalsBody;
jsize hlensLen, hvalsLen;
int i;
// lengths
huffLens = (*env)->GetObjectField(env,
table,
JPEGHuffmanTable_lengthsID);
hlensLen = (*env)->GetArrayLength(env, huffLens);
hlensBody = (*env)->GetShortArrayElements(env,
huffLens,
NULL);
CHECK_NULL_RETURN(hlensBody, FALSE);
if (hlensLen > 16) {
/* Ignore extra elements of bits array. Only 16 elements can be
stored. 0-th element is not used. (see jpeglib.h, line 107) */
hlensLen = 16;
}
for (i = 1; i <= hlensLen; i++) {
huff_ptr->bits[i] = (UINT8)hlensBody[i-1];
}
(*env)->ReleaseShortArrayElements(env,
huffLens,
hlensBody,
JNI_ABORT);
// values
huffValues = (*env)->GetObjectField(env,
table,
JPEGHuffmanTable_valuesID);
hvalsLen = (*env)->GetArrayLength(env, huffValues);
hvalsBody = (*env)->GetShortArrayElements(env,
huffValues,
NULL);
CHECK_NULL_RETURN(hvalsBody, FALSE);
if (hvalsLen > 256) {
/* Ignore extra elements of hufval array. Only 256 elements
can be stored. (see jpeglib.h, line 109) */
hlensLen = 256;
}
for (i = 0; i < hvalsLen; i++) {
huff_ptr->huffval[i] = (UINT8)hvalsBody[i];
}
(*env)->ReleaseShortArrayElements(env,
huffValues,
hvalsBody,
JNI_ABORT);
return TRUE;
}If someone wants to check it out on GitHub, here is the link to the file jdk/src/java.desktop/share/native/libjavajpeg/imageioJPEG.c. The function starts at line 746.
Although the problem can be seen in the provided code snippet, to understand the visible part of the problem, you need to look at the neighboring header files.
Hidden text
Actually, the problem is in the 46th line of the fragment above or the 791st line on GitHub.
Note that one variable hvalsLen is checked, but the value of another variable hlensLen is changed, which is not used further in the code. So if hvalsLen is greater than 256, then the references in the 49th line will go beyond the expected limit.
Now let me explain why this is especially bad. The fact is that hvalsBody is a fixed-size array of 256 elements. Memory for this array (or rather for the structure, a field of which is this array) is allocated on the heap, so potentially it looks like a heap buffer overflow (CWE-122).
Now let's start reasoning logically and with a lyrical digression. When I conduct triage of warnings, I assign one of the following possible statuses: "potential error", "unlikely error", "not an error", and "false positive analyzer".
False positive of the analyzer. Exactly what is written – the code analyzer gave out some nonsense (maybe the parser broke or some other logic glitched). In general, the analyzer is lying.
Not an error. The analyzer is generally right with its warning, but for some reason, this is not an error.
Potential error. This is what I write when I see a serious flaw in the code. But I am cautious – it is not always possible to guess what the error will actually turn out to be, so I still write "potential".
Unlikely error. This is the most interesting – I see a problem in the code, but at the same time, I understand that the strange code is in a rather inconspicuous place. And here the following situation arises. If the problem were serious, the code would constantly crash or work poorly. But in most cases, the crashes are not that frequent. So there is some trick here, for example, even if I do not see any restrictions in the code, they may still exist somewhere.
In the code fragment that was above, there is a clear situation of an "unlikely error": if the virtual machine crashed due to a crooked jpeg image, it would have been discovered long ago. So, probably, the problem is not that serious, and perhaps the check for 256 is redundant and is actually provided by logic, not by this very check.
I went online with this question because I leave the study of standards to weak-willed people. And I found a wonderful code in Python that decodes jpeg. Here I truly believed that this is my way – analyzing the java runtime code written in c++ by studying the python code.
For my purposes, everything turned out to be quite simple - at the beginning of the file 0xFFD8, at the end of the file 0xFFD9, and between them we just insert a block with the header 0xFFC4, after which there are two bytes of length (which gives a potential 65535, which is much better than 256), a descriptor byte, and then properly formed arrays of these 16 and 256+ bytes.
IrfanView gives a quite honest error "Bogus Huffman table definition", apparently, it knows something. But we are testing not IrfanView, but OpenJDK. So we download the runtime binaries, enable plugins in vscode, and write our short masterpiece.
try {
BufferedImage img = ImageIO.read(new File("C:\tmp\huffman.jpg"));
} catch (IOException e) {
System.err.println(e.getMessage());
}The result of the run, unfortunately, is not a starting calculator, but just the same error: Bogus Huffman table definition.
Further, it gets boring and sad: we find the message on GitHub. And then its usage in different files.
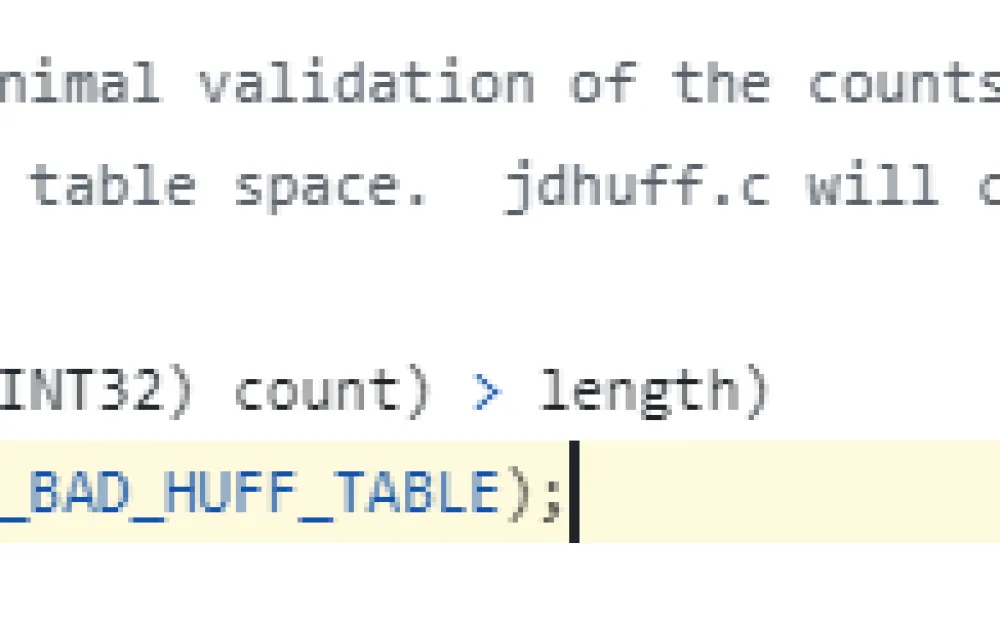

In general, the heap, so to speak, did not overflow, the simple option did not work. Well, okay, at least I found where it is checked in the code.
An attentive programmer may reasonably notice that I tried to cut corners loading the image and calling that function with the error are not generally related. That is, the check carried out, to put it mildly, does not cover all cases and, since I started, I need to check properly. The real scenario looks like this: read the image, worked with it, and somewhere after that, the aforementioned function was called.
On the one hand, it is extremely logical. During loading, the check was performed, but then something was done with the picture, as a hypothetical example - it was rotated, and so, suddenly, it turned out that the Huffman table became wider.
On the other hand, if you use common sense, the vulnerability becomes a problem only if it can be triggered in some ready-made code. If you need to write a special code in Java to trigger it, it doesn't make much sense. In general, simple things can be done, complex ones cannot.
What conditions must be met for an error to occur? hvalsLen must be more than 256 elements, and this array is taken as the JPEGHuffmanTable_valuesID field in the table object class, which is passed as jobject table to the setHuffTable function. Let's see who calls the function under consideration: there are only two options, and both are in the setHTables function in the same file. We continue to build the call stack up, in the calls the table argument is passed as elements of the jobjectArray DCHuffmanTables and jobjectArray ACHuffmanTables arrays, which are both arguments of the setHTables function. Very convenient, let's go higher.
The setHTables function is called in three different places. But the names of the calling functions are very specific and clearly indicate that they have Java prototypes, and the arguments for setHTables are passed as arguments of the corresponding functions without processing. So let's immediately look for native in the Java code.
Java_com_sun_imageio_plugins_jpeg_JPEGImageReader_readImage
Java_com_sun_imageio_plugins_jpeg_JPEGImageWriter_writeTables
Java_com_sun_imageio_plugins_jpeg_JPEGImageWriter_writeImage
The arguments of these functions that interest us are of type JPEGHuffmanTable. The constructor of this class greets us with joyful checks.
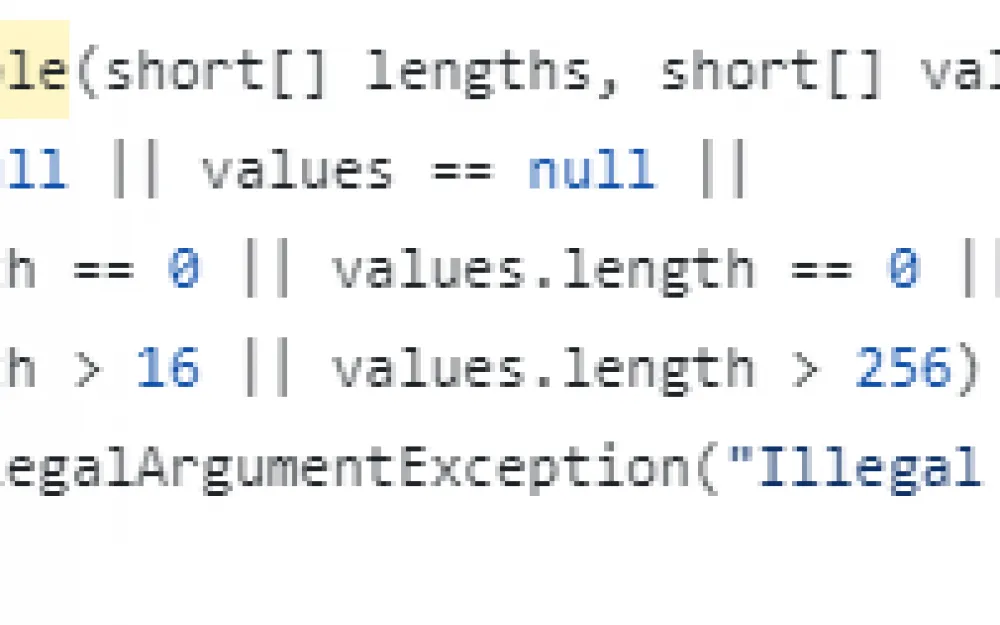
This constructor cannot create an object with a values field longer than 256 elements. The field itself is private, and its value is returned through a copy, which excludes the possibility of external modification.
The last option to spoil the object remains – the second constructor, which fills the fields without checks.

But there is nothing much to check here – the constructor is private, the comment says it is for internal use, and it is called on quite constant data. So, we can summarize.
The general conclusion we can make is this: despite the obvious typo in the check, it cannot affect the security of openJDK. A malformed image will go through several checks during loading, which will not allow it to access beyond the allocated memory. No correct interactions in java will allow us to create an object processed in this function so that it implements a buffer overflow.
That's all. I promised a 20-minute adventure.
And a little bit of rambling at the end of the article. Did I inform the developers, did I send them a patch, a pull request, or something else? Nope. There are even several reasons for this. In fact, the error does not deserve special attention, that's one. I don't know what is better in this case – to fix the check or remove it altogether, that's two. From the OpenJDK site, I did not understand where it would be correct to write about this at all, that's three. I was too lazy, that's four.










Write comment