
- Security
- A
Implementation of the "Magma" cipher in RUST
Hello! Today we continue to implement encryption. In this article, we will look at the Magma cipher algorithm, which was developed and used in the USSR.
Hello! Today we continue to implement encryption. In this article, we will look at the "Magma" cipher algorithm, which was developed and used in the USSR.
The implementation of the "Magma" cipher in Rust will use its own library, which we started writing in the previous article on block cipher modes.
The "Magma" cipher has several identifiers:
GOST 28147-89 was used in the USSR and this was the first publication of the cipher.
GOST R 34.12-2015 has been used since 2015. Under this identifier, two ciphers were hidden: "Magma" and "Kuznechik".
GOST 34.12-2018 has been used since 2018 and is already an interstate standard.
Each of them hides almost the same cipher, the difference lies only in the constants used - substitution nodes and the direction of data reading.
Characteristics and details
The "Magma" cipher is a cryptosystem based on the iterative Feistel network scheme.
One of the methods for constructing block ciphers is the Feistel network. It consists of cells, each of which receives data and a key at the input and outputs modified data and a key. All cells are the same, and the network can be considered as a repeatedly repeating structure.
The key is selected depending on the algorithm and changes when moving from one cell to another. The same operations are used for encryption and decryption, but the order of the keys is different.
"Magma" uses:
Block length - 64 bits (8 bytes).
Key length - 256 bits (32 bytes).
Number of iterations - 32 iterations.
Accordingly, the Feistel network of the "Magma" cipher consists of 32 cells, each of which receives data (8 bytes) and an iterative key (4 bytes) at the input.
Algorithm
To implement the "Magma" cipher, the following functions and transformations are needed:
Formation of iterative keys.
Transformation t.
Transformation g.
Encryption function.
Decryption function.
The algorithm itself, as well as its individual transformations, is quite simple.
Let's immediately set several necessary constants:
/// Block size: 64 bits
const BLOCK_SIZE: usize = 8;
/// Key size: 256 bits
const KEY_SIZE: usize = 32;
/// Number of encryption rounds: 32
const ROUNDS: usize = 32;And create the cipher structure:
/// # Cipher "Magma"
///
/// - Block size: 64 bits
/// - Key size: 256 bits
/// - Number of encryption rounds: 32
#[derive(Debug, Clone)]
pub struct Magma {
round_keys: [u32; ROUNDS],
matrix_pi: u8; 16]; 8],
}We will need to create and store iterative keys. In addition, the "Magma" cipher can use different substitution nodes, so you can add storage functionality to avoid hardcoding any one.
1. Formation of iterative keys
Let's start with what we already know:
Key length — 256 bits (32 bytes).
Number of iterations — 32 iterations.
And add new information:
Length of the iterative key — 32 bits (4 bytes).
It turns out that from 32 bytes of the encryption key, we need to get 128 bytes of iterative keys, that is, 4 times more.
The algorithm for forming iterative keys is extremely simple:
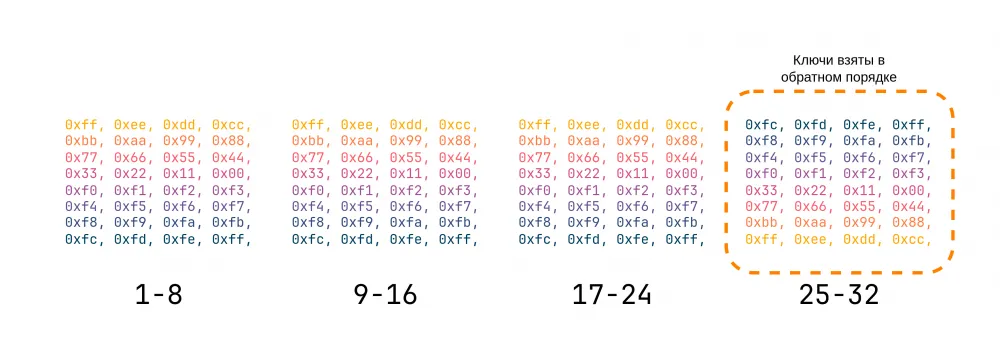
The first 24 keys are obtained simply by dividing the encryption key into parts of 4 bytes — we get 8 parts (keys). These 8 parts are simply repeated 3 times to get 24 keys.
The last 8 keys are obtained in almost the same way. We need to divide the encryption key into 8 parts, and then take them in reverse order, that is, the first key will be the part with the ordinal number 8, the second — 7, and so on.
Thus, 32 iterative keys are formed.
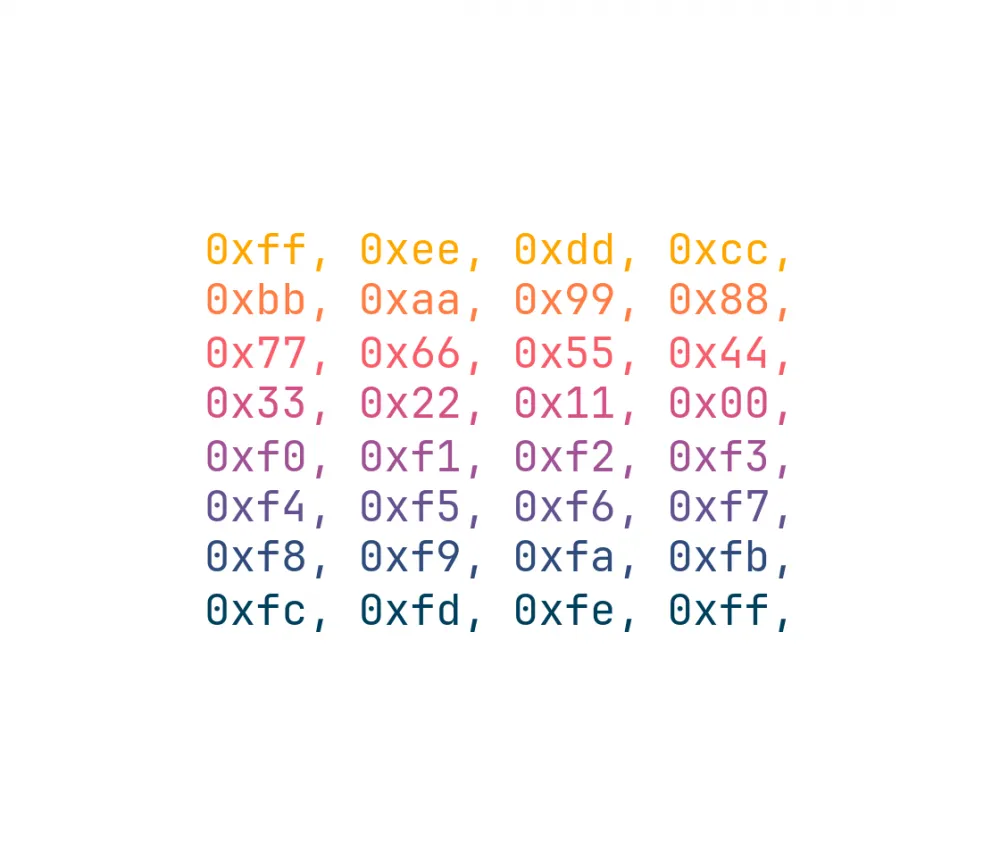
// The first 24 round keys
// in the order 0, 1, 2, 3, 4, 5, 6, 7
let mut round_keys = [0u32; ROUNDS];
for i in 0..3 {
for (j, chunk) in key.chunks_exact(4).enumerate() {
let key = u32::from_be_bytes([chunk[0], chunk[1], chunk[2], chunk[3]);
round_keys[j + 8 * i] = key;
}
}
// The last 8 round keys
// in the order 7, 6, 5, 4, 3, 2, 1, 0
for (j, chunk) in key.chunks_exact(4).rev().enumerate() {
let key = u32::from_be_bytes([chunk[0], chunk[1], chunk[2], chunk[3]);
round_keys[j + 24] = key;
}2. Transformation t
It won't get more complicated than this transformation, although it is quite simple in itself. The t transformation takes and returns a 32-bit sequence.
This nonlinear transformation divides the 32-bit sequence into 4-bit parts, then substitutes them according to the \pi table and reassembles them back into a 32-bit sequence.
Let's start by dividing the 32-bit sequence into 4-bit parts.

For ease of perception, I have converted the values to decimal representation.

Code
/// # Substitution table RFC 7836
pub const ID_TC26_GOST_28147_PARAM_Z: u8; 16]; 8] = [
[0x0c, 0x04, 0x06, 0x02, 0x0a, 0x05, 0x0b, 0x09, 0x0e, 0x08, 0x0d, 0x07, 0x00, 0x03, 0x0f, 0x01],
[0x06, 0x08, 0x02, 0x03, 0x09, 0x0a, 0x05, 0x0c, 0x01, 0x0e, 0x04, 0x07, 0x0b, 0x0d, 0x00, 0x0f],
[0x0b, 0x03, 0x05, 0x08, 0x02, 0x0f, 0x0a, 0x0d, 0x0e, 0x01, 0x07, 0x04, 0x0c, 0x09, 0x06, 0x00],
[0x0c, 0x08, 0x02, 0x01, 0x0d, 0x04, 0x0f, 0x06, 0x07, 0x00, 0x0a, 0x05, 0x03, 0x0e, 0x09, 0x0b],
[0x07, 0x0f, 0x05, 0x0a, 0x08, 0x01, 0x06, 0x0d, 0x00, 0x09, 0x03, 0x0e, 0x0b, 0x04, 0x02, 0x0c],
[0x05, 0x0d, 0x0f, 0x06, 0x09, 0x02, 0x0c, 0x0a, 0x0b, 0x07, 0x08, 0x01, 0x04, 0x03, 0x0e, 0x00],
[0x08, 0x0e, 0x02, 0x05, 0x06, 0x09, 0x01, 0x0c, 0x0f, 0x04, 0x0b, 0x00, 0x0d, 0x0a, 0x03, 0x07],
[0x01, 0x07, 0x0e, 0x0d, 0x00, 0x05, 0x08, 0x03, 0x04, 0x0f, 0x0a, 0x06, 0x09, 0x0c, 0x0b, 0x02],
];Next, we will need the Pi matrix. With its help, we will perform the substitution. By dividing the 32-bit sequence into 4-bit parts, we will get 8 parts. For each part, we will use its own row.
It is interesting that the substitution nodes can vary. The text of the GOST 28147-89 standard states that the supply of substitution node fillings is carried out in the prescribed manner, that is, by the algorithm developer.
For example, Wikipedia contains 6 substitution nodes: 4 for CryptoPro, 1 from RFC 7836, and 1 used in Ukraine.
Since the values are 4-bit, we will definitely not exceed 16 values in a row.
We will start the substitution from the end of the sequence, that is, for the first row we will use the lower 4 bits of the sequence.

This is roughly how it should look.
After the substitution, it is necessary to reassemble the 32-bit sequence, not forgetting the order.

Thus, we have defined the transformation t.
fn transform_t(&self, value: u32) -> u32 {
let mut result: u32 = 0;
for (i, row) in self.matrix_pi.iter().enumerate() {
let part = (value >> (4 * i)) & 0x0f;
let substituted = row[part as usize] as u32;
result |= substituted << (4 * i);
}
result
}Here I use regular shifts and a 0x0f mask to select only 4 bits. Then I use the obtained value as an index to get an element in the row and complement the resulting value on the spot.
3. Transformation g
The g transformation works with two 32-bit numbers a and k, and returns only one 32-bit number as a result.
This transformation is even simpler and consists of only 3 actions:
It is necessary to add the numbers
aandk, discarding the overflow (addition modulo 32).The result of the addition must be passed to the t transformation.
The result of the t transformation must be cyclically shifted to the left by 11 positions.
fn transform_g(&self, a: u32, k: u32) -> u32 {
let temp = a.wrapping_add(k);
let substituted = self.transform_t(temp);
substituted.rotate_left(11)
}At this point, the auxiliary functions are finished, and now we can move on to encryption.
4. Encryption Function
For encryption and decryption, obviously, the same actions are used, but first, let's consider encryption.
First, we divide the incoming data block exactly in half.
let mut a0 = u32::from_be_bytes([block[0], block[1], block[2], block[3);
let mut a1 = u32::from_be_bytes([block[4], block[5], block[6], block[7);We will alternate working on each part. These will be the Feistel network cells. Each time we will supply the data (2 parts of 4 bytes each) and the iteration key, and there will be 32 such cells in total.
for i in 0..32 {
let temp = a1;
a1 = a0 ^ self.transform_g(a1, self.round_keys[i]);
a0 = temp;
}Each time we will pass the second part of the data to the input of the next cell. In this one, we will simply perform the XOR operation, and as operands, we will pass the first part of the data and the result of the g transformation, the operands of which, in turn, are the second part of the data and the iteration key.
let mut result = Vec::with_capacity(BLOCK_SIZE);
result.extend_from_slice(&a1.to_be_bytes());
result.extend_from_slice(&a0.to_be_bytes());At the end of the encryption, we assemble the block back, placing the second part first. This is how simple block data encryption is arranged.
5. Decryption Function
let mut a0 = u32::from_be_bytes([block[0], block[1], block[2], block[3);
let mut a1 = u32::from_be_bytes([block[4], block[5], block[6], block[7);As in the case of encryption, we divide the data into 2 parts.
for i in (0..32).rev() {
let temp = a1;
a1 = a0 ^ self.transform_g(a1, self.round_keys[i]);
a0 = temp;
}We perform exactly the same operations with the only difference in the applied iteration keys — we use them in reverse order.
let mut result = Vec::with_capacity(BLOCK_SIZE);
result.extend_from_slice(&a1.to_be_bytes());
result.extend_from_slice(&a0.to_be_bytes());And again we assemble the data block, not forgetting to submit the second part first.
Verification and reference values
Verification was carried out in two ways:
Using reference values from RFC 8891.
Using CyberChef.
Reference values
The RFC 8891 document thoughtfully provides reference values for all transformations and functions used.
Thus, we can be sure that we can encrypt at least one block of data correctly.
In this article, I will not provide these values, you can find them either in my repository — there is already ready-made test code, or in the document RFC 8891.
CyberChef
At the end of such materials, I would always like to use someone else's public implementation to verify my own solution on arbitrary data. I was surprised that nothing was found for the online encryption request using "Magma".
Somehow I found that CyberChef contains implementations of both "Magma" and "Kuznechik", but with one feature — CyberChef does not work with padding.
Comparing the results, I noticed that everything always converges except for the last block. After a short search, I found that CyberChef does not pad data according to the PKCS5/7 algorithm (essentially the same, except for minor details).
Principle of PKCS5/7
For those who do not know or have forgotten, I remind you that this is a very simple algorithm that fills the block's void with bytes whose values are equal to the number of missing bytes.
Example: if we have a block of 8 bytes and 3 bytes are missing, the padding will look like:
[0x03, 0x03, 0x03].
Very simple. In addition, if padding is not required, it will still be performed as if we needed to fill a completely empty block. This is a PKCS5/7 requirement.
Example: if we have a block of 8 bytes and the data size is a multiple of the block size, the padding will look like:
[0x08, 0x08, 0x08, 0x08, 0x08, 0x08, 0x08, 0x08].
In this CyberChef failed. Maybe I'm missing something, although I double-checked everything several times.
Nevertheless, CyberChef can be used by making additions manually. In this case, all encryption modes: ECB, CBC, CFB, OFB, CTR work correctly.
Verification Conclusion
running 7 tests
test tests::cipher::magma::decrypt_test::test_decryption ... ok
test tests::cipher::magma::encrypt_test::test_encryption ... ok
test tests::cipher::magma::keys_test::test_invalid_key_lenght - should panic ... ok
test tests::cipher::magma::keys_test::test_invalid_zeroed_key - should panic ... ok
test tests::cipher::magma::keys_test::test_key_generation ... ok
test tests::cipher::magma::transform_g_test::test_transform_g ... ok
test tests::cipher::magma::transform_t_test::test_transform_t ... ok
test result: ok. 7 passed; 0 failed; 0 ignored; 0 measured; 16 filtered out; finished in 0.00sAll tests used a small amount of data, a few bytes, although it would be more correct to compare by encrypting a large object, such as a video.
Nevertheless, the fundamental functions work correctly, the composite functions, such as encryption and decryption, work correctly, and even higher-level functions, such as encryption in a specific mode, also work correctly.
Conclusion

digit4lsh4d0w
Author
In the comments, you can often find statements that creating your own cryptography is unacceptable. It seems that the authors of the comments rely solely on the title and the first paragraph.
Of course, using your own cryptography on real working servers, even for personal purposes, is strictly prohibited. Hundreds of nuances cannot ensure the security of your data.
However, the nature of this note indicates that this is just a modest attempt at implementation, intended for those who do not want to spend a lot of time studying the basics of the algorithm. My notes consider the algorithms themselves, not industrial use or cryptography issues.
The entire cycle of materials resulted from scattered, poorly designed, and sparse articles on the SHA algorithm. Therefore, I prepared my materials in the way I would like to perceive them myself.
I would be glad to hear reasoned criticism of my material and my position in the comments, both here and in Telegram.
All code is saved in the GitVerse repository.
Finally about Rust
Sometimes you can hear the question: "Why do you write in Rust? Wouldn't Python be more understandable?"
Yes and no. For me, it is more interesting to use a new, low-level, and conceptually complex language like Rust. I like its concept and implementation, but I don't have tasks that would require its use. Therefore, I try to find a balance between learning and creating notes for others.
In addition, Rust allows you to explicitly specify what and where is moved. This can be useful. Python, on the other hand, creates abstractions, which is not always convenient for me.
For those who do not want to learn Rust or do not want to perceive my code as pseudocode (which, in general, is not difficult), I can recommend using LLMs such as GigaCode. These tools will accurately translate the code into any convenient programming language. I received some information on the implementation of certain algorithms in this way, for example, by converting code from Java.







Write comment