- Security
- A
Inventing IAM for the MWS cloud: introduction and resource model
My team and I decided to create a cloud. Not the kind of cloud that says "move your files to the cloud," and not even the kind that says "deploy your site on our CMS, domain included." But the kind that comes to mind when you use the word "hyperscaler."
I, Andrey Khaliullin, am responsible for the development of the IAM (Identity and Access Management) service for the new MWS cloud platform. Since we want to maintain an open dialogue with the market and the community as much as possible, at some point I was tasked with stopping writing IAM and starting to write an article about how we write IAM. I have a lot to share about researching the cloud provider market, reverse engineering product and technology solutions, technical challenges in terms of reliability, scalability, and managing the product complexity of services, and even attempts to understand "What is IAM?"
After several attempts at this article, I managed to touch on the surface of the topic of resource management in the cloud — and so the article turned into the idea of a series of articles about IAM development.
In this text, I will provide some background on why IAM is needed, and then I will talk about the levels of the resource model of an abstract cloud provider with comments on why each level is needed and what we think about it at MWS. And then — stay tuned to our hub.
Why IAM is needed in services
Access control is an integral part of any modern service, whether it is a social network or a cloud platform. The access management model of a service determines which subjects (users, employees, robots) are allowed access to which resources (money in a bank account, posts on a social network, or virtual machines in the cloud) and how these accesses can be managed.
B2C services, as a rule, implement a relatively simple and straightforward access management model: whoever created the resource manages it. The system should be simple so that each of the millions of customers can use the service without having to read a 500-page access management documentation. And B2C services, as a rule, can afford a simple system based on their scenarios. Who can edit a post on social media? Obviously the same person who created it - the owner of the post. The model of "ownership" of resources is actually a digital reflection of the usual model of human interaction with resources in the real world: as the owner of a car, I can drive it, I can not drive it. I can sell it, lend it to a friend, or take it apart for parts and make swans for the garden out of the tires.
B2B services, in turn, have a more elaborate access management model. The client of a B2B service is a company, whose employees must have different sets of permissions in relation to various company resources. Moreover, the ownership-based management model is poorly suited for quality process and security management in an organization. It would be somewhat surprising if a builder could remove a brick from a building just because "I put it there - so I can take it back." The organization itself owns the resources and access rules to them.
The truth is that the "organization" does not enter the cloud interface and does not distribute access. In B2B services, including cloud platforms, company employees receive rights in accordance with their job functions - from managing virtual machines to managing the rights of other users. To make it even more interesting - the staff of a real organization, just like the ship of Theseus, can be replaced "board by board" with a completely new set of employees performing work in the B2B service, and this should not affect the operation of the service, which will continue to "obey the instructions" of the organization's employees endowed with certain roles.
"Big Three" entities
Any access control system, oddly enough, controls access. At a basic level, this means that the key task of IAM in the cloud is to answer the question of whether an action is allowed when performing any action in the system (for simplicity, with any API call). To unify the access control process, it is necessary to somehow formalize and derive a general model of this decision-making process.
Most models boil down to the fact that any action in the system is broken down into three components:
Resource: what the action is performed on.
Subject: who requested the action.
Action type: what exactly is happening.
Thus, the decision to allow any action comes down to the question "can subject X perform action Y on resource Z?", and IAM becomes a "system for managing the relationship of three verticals" - it sounds simple. Let's look at the details and discuss working with resources in the cloud.
Resource Model
What is a resource model? Cloud resources must "live somewhere". I'm not talking about the physical allocation of hardware, but about the logical ownership of resources. As we have already found out, the client of a B2B service is an organization, and the client would like to have their resources in one place. This "one place" cannot be the human account of some "super-admin-owner-founder", because, as we understand, living people are quite inconsistent in terms of where they work today, tomorrow, and the day after tomorrow.
In any cloud, client resources live in some abstract containers. The similarities of clouds end here and the differences begin.
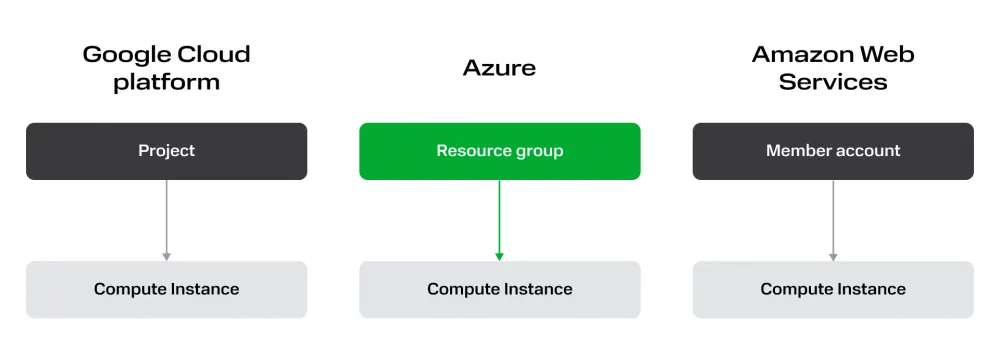
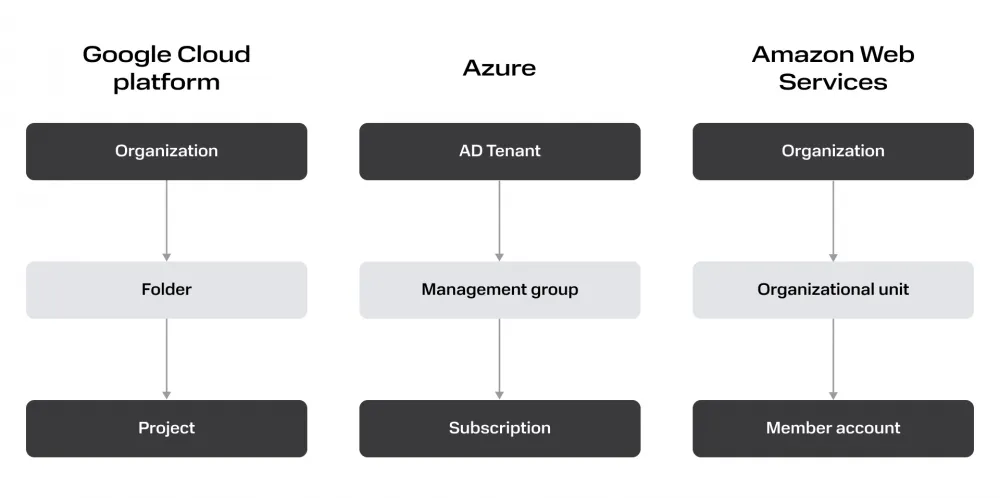
The first thing that catches your eye is the different names. But this is not the most exciting part, the much more interesting subtle semantic difference, which is highlighted in color.
The picture shows a kind of "bottom-up view": these are containers in which computing resources are located at different cloud providers. DevOps engineers interact with these containers most of the time. But Resource Group in Azure is not a direct analog of Project in GCP, despite the fact that they are "leaf containers" in the resource models of their clouds. The fact is that a separate billing account cannot be attached to the Resource Group or quotas managed, but it can be done on the GCP Project.
If you build the picture a little higher, you can see that Azure still has an analog of the project, it is called Subscription. This is not a leaf container - cloud resources are not created in it.
To eliminate confusion in terminology, let's introduce an abstract term to denote the layer of the resource model on which quotas are controlled and billing is managed - let's call it "tenant".
Why is this difference in the semantics of resource hierarchy layers so important? Containers, or levels of the resource hierarchy, in addition to the task of grouping similar resources for convenience, solve a number of other tasks for both the cloud provider and its customers. And most of these tasks come down to different types of isolation.
Let's imagine that I have a large IT business with a dozen separate product teams. Each team develops its own product, each product must exist in at least two environments: production and testing. How do I land my business on the provider's resource model with resource groups?
At first glance - well, let's give each product team a tenant, and they will figure it out inside themselves - they will cut their tenants into resource groups for prod, testing and other environments. It looks pretty good, each product requests the quotas it needs from cloud support, while if desired, you can even assign different billing accounts to different product teams to pay for the infrastructure of the products independently.
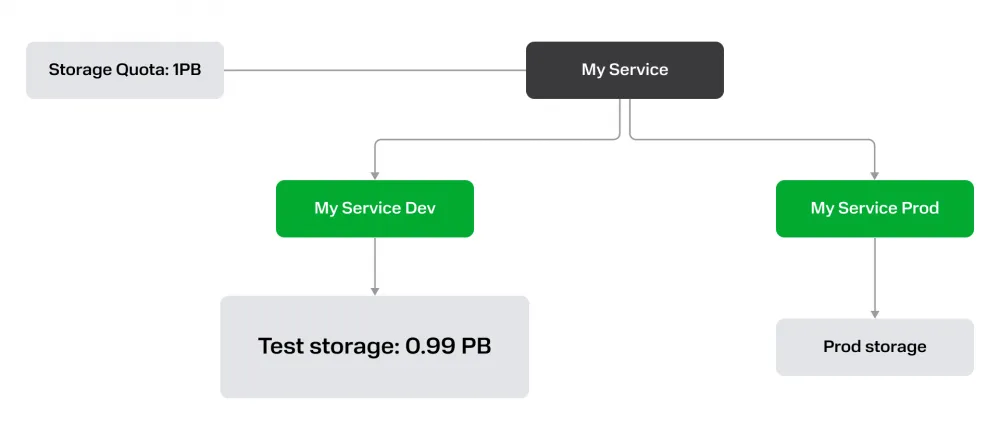
Problems start when developers, as part of their research activities, pour a couple of hundred TB of test data into the dev bucket, consuming the quota for the volume of Object Storage product in all environments at once. Or when the team lead in their dev environment runs Kubernetes with all the money and forgets to turn it off, spending the product's entire budget on infrastructure. The outcome of both scenarios is the failure of the client's products in production.
The root of the problem is that the resource group as a concept cannot provide full resource isolation. There is currently no consensus in the cloud provider market on how useful or harmful resource groups are. On the one hand, it is just an additional functionality that the client can use or ignore. On the other hand, the very existence of such an abstraction often pushes clients to use anti-patterns when designing the resource model of their organization.
At MWS, we decided not to introduce resource groups in our cloud. Moreover, another trend is gradually spreading across the clouds — tags.
Tags are a subject for a whole article, and I hope someday we will write it, but in short — support for structured tags with access control implementation in all cloud resources allows not only to solve the same tasks that resource groups solve (grouping for easier navigation, access delimitation, budget expenditure detailing, and much more), but also allows solving it "in several dimensions".
In addition, tags, due to their optionality, can be added to the cloud resource management model at any time, unlike resource groups. Yes, some cloud providers have made changes to their resource models during their development, but changing the type of leaf container in the cloud is a non-trivial change in the contract between IAM and dozens of cloud services, the game is not worth the candle.
Organizations
Let's jump straight to the top of the resource hierarchy. Hallway surveys show that a significant portion of developers have a hard time understanding the meaning of "organization" in the cloud, while the rest are unaware of the existence of "organizations" at all.
Almost any developer who registers in the cloud "from the street" spends the first few minutes of getting to know the service wading through the thickets of unnecessary information and interfaces to finally get the first tangible resource - a deployed virtual machine. When he finally gets the virtual machine, he begins to explore the landscape. By this time, he has already agreed to the EULA, given his credit card information somewhere, and without thinking, agreed to create the entire vertical resource model "somehow" to get the very container in which resources are attached in this particular cloud.
The truth is that in the process of exploring the cloud, deploying pet projects, and even administering a real commercial project, a rare developer feels the need to look into the resource hierarchy above the tenant and see what is happening there.
But as we discussed above, the tenant is an isolation unit. If a company develops several products or even if the company needs a test environment for its product (you have a test environment, right?) - the company is forced to have several tenants in the cloud. Nevertheless, there must be some way to combine these containers. Surely the company will want to reuse payment accounts between some projects, share access between employees. In some cases, set up cross-tenant joints, somehow centrally manage security settings, and just see all your tenants in one place, after all. It is these tasks that the "organization" level solves. Providers approach the name of this layer of the hierarchy relatively consistently.
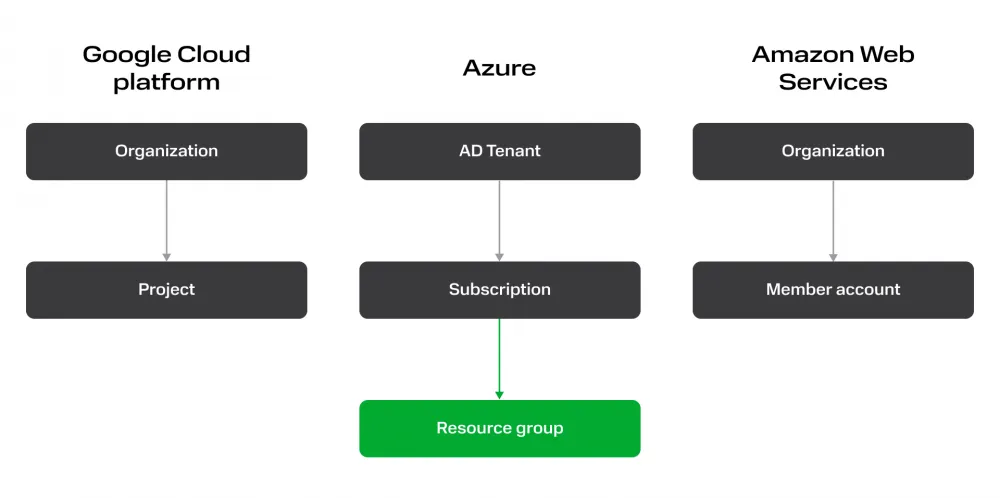
In an ideal universe, one real-world organization corresponds to one "organization" of the cloud provider.
In addition to the fact that the "organization" contains tenants with end resources - such as virtual machines and other entities from which the client builds its computing infrastructure, the "organization" also serves as a direct container for some resources that would be strange and inconvenient to place directly in tenants.
In general, the "organization" management layer differs so significantly in terms of usage scenarios and even the set of employees who manage this "organization" that most providers move the web interface for managing the organization to a separate domain with a different console structure. If we draw an analogy with something physical, then the resource management console in tenants is the control panel of a spaceship, and the organization interface is the flight control center.
Within a tenant, developers, devops engineers — in general, IT specialists responsible for the development and deployment of products and infrastructure — usually reside. The users of the organization management console are somewhat more complex. Usually, these are employees of the client security service, AD administrators, financiers, and others.
Speaking about the MWS cloud — in the case of "organizations," we did not reinvent the wheel and introduced such a container from the start of the new cloud's existence. However, some decisions had to be made at this level as well. For example: "Should the organization be a mandatory element when creating a project?" Competitors often offer the user to simply create a project. As far as can be assessed from the outside, there are at least two reasons for such a proposal:
— Historical. For a wide range of scenarios, tenants are sufficient for clients. This means that the first version of the cloud can be launched without complications in the form of "organizations." But if organization support appears in the service evolutionarily to meet the requirements of larger clients, the provider finds itself in a bipolar configuration with "organizational" and "non-organizational" tenants, at least for the migration period.
— Product. Excessive complexity on the user's path when going through the scenario leads to a decrease in conversion. And although the goal of this entire article is to explain that all this is important and necessary, in fact, not only large enterprise customers use clouds, but also smaller commercial clients and even individuals. And on this territory, the rules of B2C service begin to apply: be simpler or be trampled. This explains the desire of some clouds to roll all complex enterprise-grade features into separate services of the "organizations" layer and hide them from the new client so as not to scare them away.
We decided to go from general to specific and, from the point of view of the basic resource model (API) of our cloud, immediately implement a "complex" system with organizations embedded in the service model from the start. The idea is that this will allow us to immediately focus on enterprise clients and design all our solutions relative to the complex version of the cloud device model, and consider the problem of getting to know the cloud as a UX problem.
Folders
Justifying the need for the existence of certain containers in the resource models of cloud providers is becoming increasingly difficult, but I will nevertheless risk continuing.
We have already figured out that a spherical company in a vacuum owns exactly one "organization" in the cloud, within which all the variety of tenants is deployed, each of which isolates something that needs to be isolated. For example, infrastructure for a specific environment of a specific product of the company.
Probably, it is already clear what I am getting at: modern technology companies can provide customers with dozens of public products. By multiplying the number of products by the number of environments, the customer will get the need to manage a rather long flat list of junk. By management, I mean not so much navigation as centralized policy implementation, access assignment, financial and security event analytics at a higher level of hierarchy than the "product environment", but more granular than "for the entire organization". In short, more layers of the model are needed to express the similarities and differences between different tenants. Of course, you can try to approach the issue with intelligence and typing.
Let's implement a separate layer for environments and a layer for products. By the way, it is interesting which of these layers should be higher? Well, let's continue. In some companies, products are organized into product groups. And there are also business units. And in different business units, theoretically, a different model of product hierarchy can be adopted. It seems that we are trying to design the structure of the ideal organization for the chamber of measures and weights here.
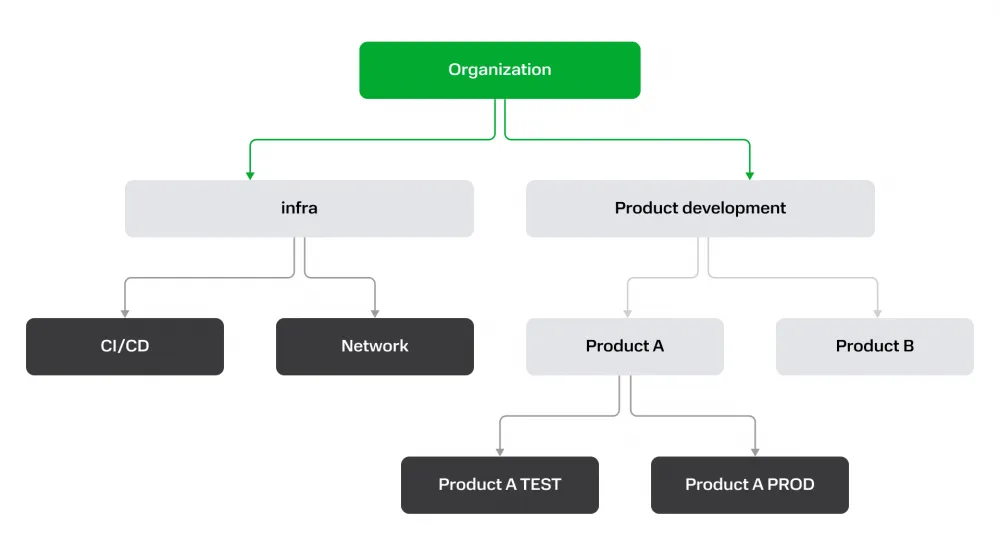
So that the cloud does not decide for the client what the topology of its resources should look like, the cloud provides the client with "wire" from which the client can assemble the framework of his organization. Folders are the only cloud container that supports "self-nesting", i.e. works like file system directories.
Folders can be used to build a resource management tree in accordance with the project management structure in a particular organization. Note that the folders I am talking about are between the "organization" and the "tenant" and serve as a link between these worlds.
Initially, I wanted to say that folders are like clay, but the metaphor didn't quite fit. Folders themselves are rather boring and low-functional resources, they only allow you to outline the contours of the management model. The clay in this metaphor will be the full power of org-level services and features that allow you to apply organizational policies, set up audit logging, organize trust boundaries, and perform budget control and analytics based on the folder structure. But that's another story.
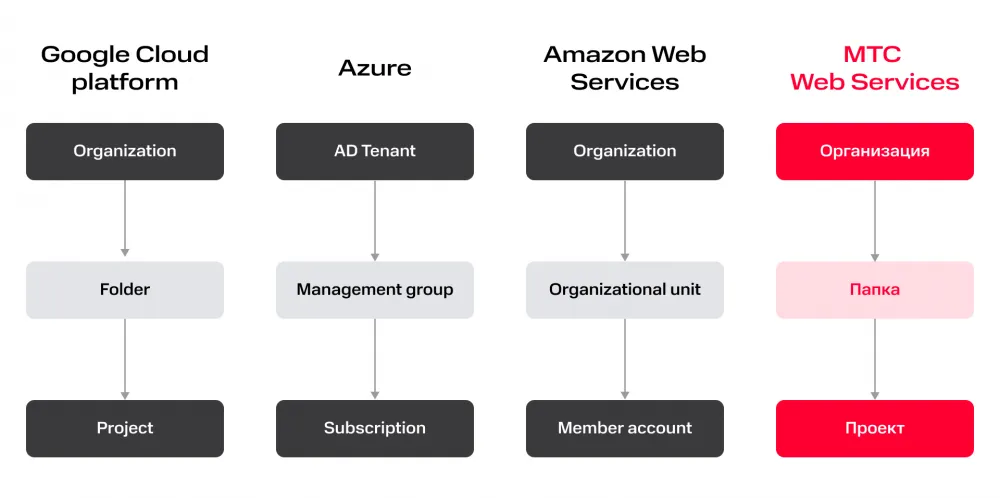
Last thought about folders. The naming of the middle layer, to put it mildly, is diverse. I have some reflections at the intersection of archeology, formal logic, and other scientific disciplines about why everything turned out the way it did. But when it comes to making a decision for our new cloud, we believe that the name Folder perfectly reflects the purpose of this resource. A folder is an abstract container, the semantics of which are given by the cloud client, not the cloud itself.
So, the overall structure of the MWS Cloud resource model will look like this:
Instead of a conclusion
A simple takeaway from this article: the cloud is complex. No, of course, the cloud has simple parts, but even they are complex if you try to design them for 5 years ahead. And the cloud is a product that cannot be designed for less than 5 years ahead.
We are now starting a series of articles on building an IAM cloud platform. We plan to talk about other entities and concepts that inhabit IAM:
Access subjects — their types, authentication methods. Managing access subjects.
Authority and role models.
Directly managing access of subjects to resources.
And with today's topic on the structure of the resource hierarchy in clouds, it's time to finish, see you in new articles, reports, and channels!








Write comment