- AI
- A
Distributed inference llama.cpp via RPC
The idea of creating this publication has been on my mind for a long time, the fact is that one of my hobbies is related to distributed computing, and another hobby is related to neural networks, and I have long been obsessed with the idea of running LLM inference on several computers, but so that they all work on the same model in parallel.
After googling for a while, I found out that the LocalAI project has supported this possibility for quite some time, so I quickly deployed this project on several computers, then made all the necessary settings, linking all the instances into a single system and, to put it mildly, was disappointed, this solution turned out to be too "fatally insufficient", the Docker image was built suboptimally, it was huge in size and only for amd64, the non-disconnectable web interface came with the project, a meager selection of models, some of the available LLMs did not work in RPC mode, all embedding models also refused to run in this mode, and so on and so forth.
After fiddling around a bit more, I went into the source code and found a mention of the llama.cpp project, then found a call to the rpc-server binary. And so I ended up on the llama.cpp/examples/rpc page and everything started spinning...
Brief(?) overview
Let's first ask GigaChat what the RPC protocol is:
The RPC (Remote Procedure Call) protocol allows programs to call functions or procedures in another address space, on remote nodes, or in independent systems on the same node. It includes a network protocol for data exchange in client-server mode and an object serialization language for encoding data when transmitting it over the network.
There are various implementations of RPC, including SOA, CORBA, and DCOM. TCP and UDP protocols are often used for the transport layer, but there are also HTTP-based implementations. Examples of RPC implementations are XML-RPC, which uses XML for message encoding and HTTP as a transport mechanism, and gRPC, which uses HTTP/2 and Protocol Buffers to describe interfaces. RPC is widely used in various network services, including NFS.
In the llama.cpp project, this protocol is implemented in a client-server format, with utilities such as llama-server, llama-cli, llama-embedding, and so on acting as RPC clients, and specialized binaries rpc-server acting as RPC servers.
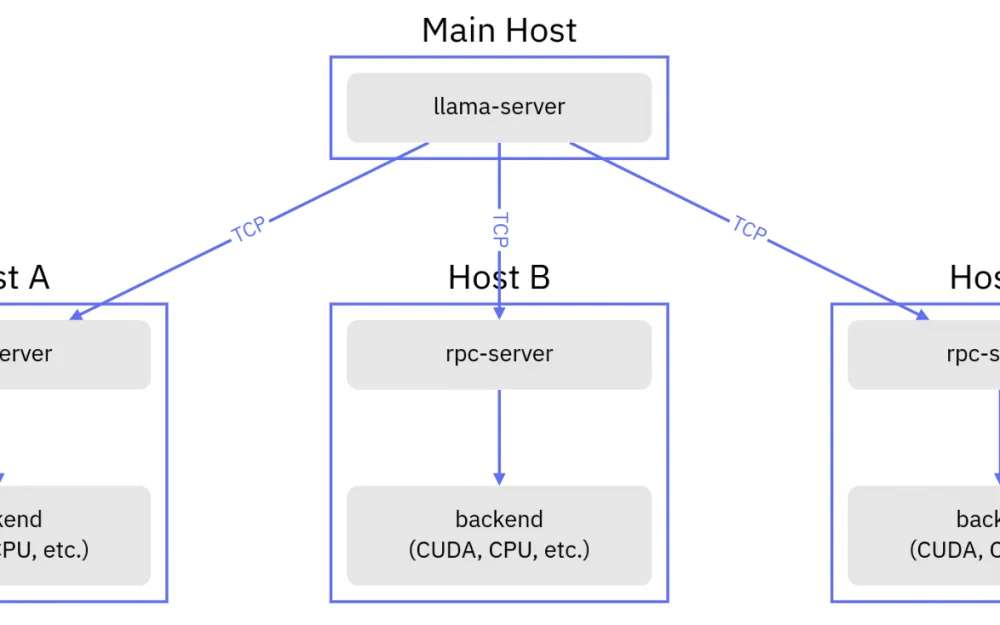
To briefly describe how all this works, it goes as follows:
-
An RPC client, say
llama-server, receives a list of RPC servers and a model through command line arguments at startup; -
The RPC client reads the model and then "slices" its layers so that they are evenly distributed among all RPC servers;
-
Then the RPC client distributes the layers across the servers and starts inference.
In general, this scheme will look as follows:
At the same time, the rpc-server can be built for different backends, which can be different processor architectures, with support for various functions. For example, you can build one RPC server for x86_64 with CUDA support, another for x86_64 without CUDA, and a third for ARM64 to run on a RepkaPi 3, and... the RPC client will be able to work perfectly with all of them and perform inference.
Building binaries
After carefully studying the instructions for building both the server and clients, I concluded that at least four binary files are needed to solve the task:
-
llama-cli- a command-line utility that allows running LLM inference; -
llama-embedding- a command-line utility that allows running embedding model inference; -
llama-server- a very simple API server that can work both in LLM inference mode and in embedding model inference mode; -
rpc-server- a binary that will run on remote machines and perform all the inference work.
So, in short, the llama.cpp build can be done in three simple steps.
-
Install the packages needed for the build:
apt install -fyq bash wget git make g++
-
Clone the repository to your host and navigate to the source directory:
git clone https://github.com/ggerganov/llama.cpp.git
cd llama.cpp
-
Start the compilation (the instructions provide an example using
cmake, but I prefermake):
GGML_RPC=ON make llama-server llama-cli llama-embedding rpc-server libggml.so libllama.so
It is important to set the environment variable GGML_RPC=ON before make (you can also use export, but I find it more convenient in inline format). This variable allows you to include code blocks that add RPC support in the build instructions.
After the compilation is complete, the executable binary files listed after make will appear in the directory.
Building Docker Images
The ability to compile binaries for different architectures is certainly useful, but what if we have, say, a dozen computers and virtual machines or a Kubernetes cluster? We won't be compiling on each node, will we? Of course not! Instead, we will use DevOps practices and build the binaries into Docker images.
For the sake of unification, the library Ubuntu 22.04 LTS was chosen as the base image, as it is also used in the base containers nvidia/cuda.
I decided to use a multi-stage build divided into two stages for the project.
In the first stage, let it perform the loading of everything necessary for compilation and the compilation itself:
FROM ubuntu:22.04 AS builder
WORKDIR /app
ARG LLAMACPP_REPO="https://github.com/ggerganov/llama.cpp.git"
ARG LLAMACPP_VERSION="master"
# Install dependencies
RUN apt update -q && apt install -fyq bash wget git make g++ && apt clean
# Clone repo
RUN git clone --branch "$LLAMACPP_VERSION" --depth 1 "$LLAMACPP_REPO"
# Build binaries
WORKDIR /app/llama.cpp
RUN GGML_RPC=ON make -j$(nproc) llama-server llama-cli llama-embedding rpc-server libggml.so libllama.so
And in the second stage, let the compiled binary files be copied into a clean base image:
FROM ubuntu:22.04
WORKDIR /app
# Install basic dependencies
RUN apt update -q && apt install -fyq libgomp1 && apt clean
# Create folders
RUN mkdir -pv /app/models
# Copy compiled tools
COPY --from=builder /app/llama.cpp/libllama.so /usr/lib/x86_64-linux-gnu
COPY --from=builder /app/llama.cpp/libggml.so /usr/lib/x86_64-linux-gnu
COPY --from=builder /app/llama.cpp/rpc-server .
COPY --from=builder /app/llama.cpp/llama-cli .
COPY --from=builder /app/llama.cpp/llama-embedding .
COPY --from=builder /app/llama.cpp/llama-server .
# Init entrypoint
ADD entrypoint.sh .
ENTRYPOINT ["/app/entrypoint.sh"]
The full Dockerfile code is in the GitHub repository.
Building Docker images with CUDA support
There are no fundamental differences from the Dockerfile based on library ubuntu, except that in the first stage of the build, the container nvidia/cuda:devel is used, and in the second stage nvidia/cuda:runtime.
# Stage 1
FROM nvidia/cuda:12.5.1-devel-ubuntu22.04 AS builder
# Stage 2
FROM nvidia/cuda:12.5.1-runtime-ubuntu22.04
The full Dockerfile.cuda code is in the GitHub repository.
About entrypoint.sh
Since I wanted to create a universal container that can be used in various modes, I had to implement a special entrypoint.sh script that will run every time the container starts.
The container is planned to work in the following modes:
backend
The mode in which the rpc-server is launched, the server start command looks like this:
rpc-server --host "0.0.0.0" --port "50052" --mem "1024"
Here you can see that there is a strange option --mem which allows you to specify how much memory (in Megabytes) this RPC server can use. If the rpc-server is built with CUDA support, this parameter specifies the amount of VRAM (video memory), if without CUDA support, then the amount of RAM (system memory).
server
The mode in which llama-server is launched, representing a simple API server that provides the ability to interactively interact with large (and small) language and embedding models, the launch command looks as follows:
llama-server --host "0.0.0.0" --port "8080" --model "/app/models/TinyLlama-1.1B-q4_0.gguf" --gpu-layers 99 --rpc backend01:50052,backend02:50052
It is important to pay attention to the --gpu-layers option, under normal circumstances it indicates how many layers can be loaded into the video card memory, however, if the --rpc option is specified, its behavior changes and it indicates how many layers can be unloaded to the RPC servers.
With the --rpc option, we list the hosts and ports of the RPC servers to which the RPC client will connect, separated by commas.
none
A special mode that launches the sleep inf command so that you can connect to the container and manually launch llama-cli or say llama-embedding.
If you put all this together in one script, you get a universal entrypoint.sh.
Cross-platform Docker image build
One of the curious features of the ubuntu library image is that it supports many processor architectures, but I was primarily interested in amd64, arm64, and arm/v7, the first one is clear why, but the last two I need to be able to run the RPC server on microcomputers, but the nvidia/cuda container is only available for amd64 and arm64 architectures.
The build itself will be performed using the docker buildx special plugin, which extends the basic functionality of Docker. In our case, we are only interested in the ability to cross-compile containers, as the build for ARM64 is planned to be performed on an x86_64 processor.
So, first, let's create a buildx builder, let's call it, say, my_builder.
docker buildx create --name my_builder --driver=docker-container
Next, let's assume that the Dockerfile and entrypoint.sh files are located in a directory called llama.cpp:
docker buildx build --builder=my_builder --platform=linux/amd64,linux/arm64,linux/arm/v7 --build-arg LLAMACPP_VERSION=master ./llama.cpp/
Here we see that the build is happening for three architectures, and the version used is HEAD from the master branch of the llama.cpp repository.
By adding the options --tag=${owner}/${repo}:${tag} and --push, we can tag the images and push them to the registry.
A complete example of building and publishing containers using GitHub Actions.
Running through Docker Compose
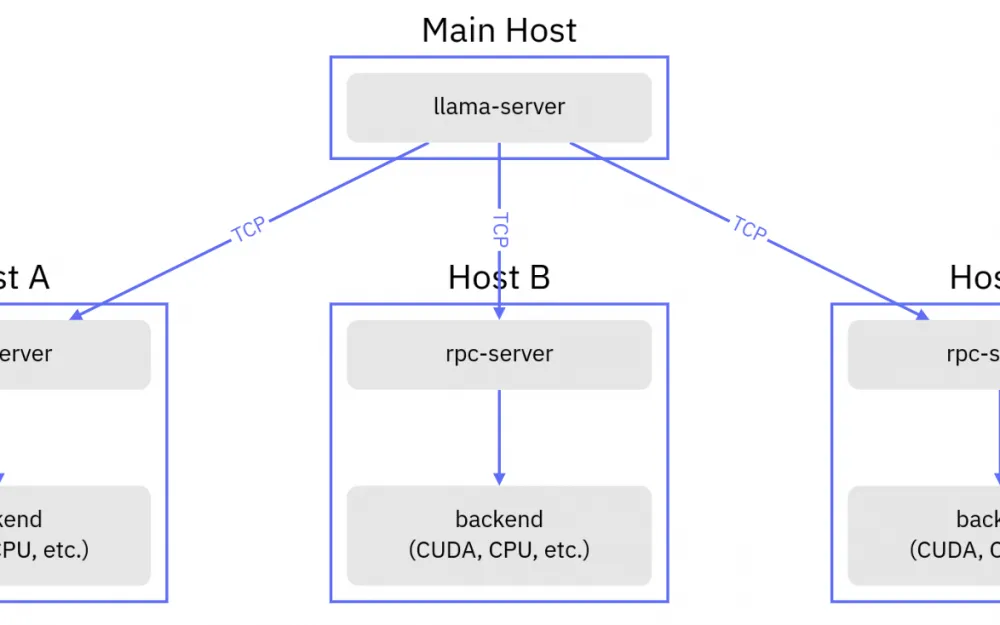
So, let's assume we have built several containers, pushed them to Docker Hub, and now want to run all this on our hardware. Let's assume we have two servers, one where we can use a graphics card, but with only 1GB VRAM, and the other without a graphics card and can only use 2GB RAM. We plan to run the TinyLlama 1.1B model on them so that the user interacts with the API server.
In general, this scheme will look as follows:
As a result, we will get the following docker-compose.yml
version: "3.9"
services:
main:
image: evilfreelancer/llama.cpp-rpc:latest
restart: unless-stopped
volumes:
- ./models:/app/models
environment:
APP_MODE: server
APP_MODEL: /app/models/TinyLlama-1.1B-q4_0.gguf
APP_RPC_BACKENDS: backend-cuda:50052,backend-cpu:50052
ports:
- "127.0.0.1:8080:8080"
backend-cpu:
image: evilfreelancer/llama.cpp-rpc:latest
restart: unless-stopped
environment:
APP_MODE: backend
APP_MEM: 2048
backend-cuda:
image: evilfreelancer/llama.cpp-rpc:latest-cuda
restart: "unless-stopped"
environment:
APP_MODE: backend
APP_MEM: 1024
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: 1
capabilities: [ gpu ]
Next, you need to create a models directory next to docker-compose.yml and download the TinyLlama-1.1B-q4_0.gguf file into it.
Start the composition with the command:
docker compose up -d
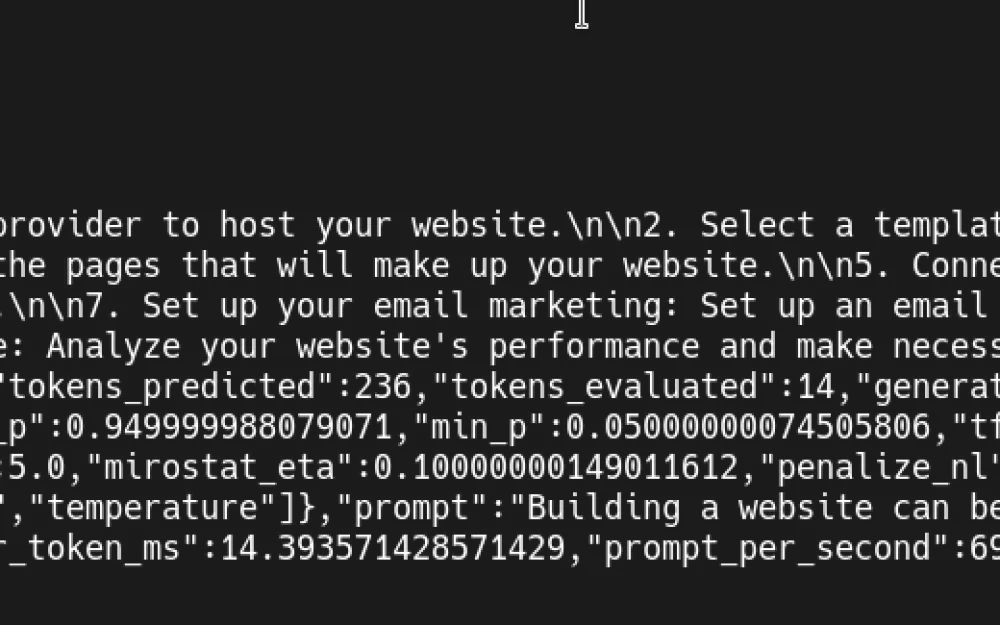
Then wait for a while, and after the composition starts, you can try to perform inference through curl:
curl --request POST --url http://localhost:8080/completion --header "Content-Type: application/json" --data '{"prompt": "Building a website can be done in 10 simple steps:"}'
The response will be something like this:
What's next?
In principle, the project is already usable, it has everything you need, and what is missing can be easily added in the future.
Of interest, I would draw your attention to this small PR in the ollama project (which at the time of publication of this article was still pending) and this discussion, also in the ollama project tickets. In short, the developers want to add the ability to perform distributed inference on RPC backends similar to what was demonstrated in this publication. So in the future, I plan to try to integrate ollama with my Docker containers.
Also, I plan to use these containers in Kubernetes, so most likely in the near future I will prepare a k8s operator or just a deployment in the format of a Helm chart to simplify the procedure for deploying servers across nodes.
Also, I have a lot of microcomputers on my mezzanine, as well as two special motherboards called TuringPi v1 for clustering RaspberryPi CM3, I also plan to conduct experiments on them in the future and that is why among all the listed container architectures there is arm/v7.
In general, there is a lot of work, if only there was time...
With that, I take my leave, thank you for reading the article to the end, if you are interested in what will happen with this project in the future, I invite you to my channel @evilfreelancer on Telegram.
Links
-
https://github.com/EvilFreelancer/docker-llama.cpp-rpc
-
https://hub.docker.com/r/evilfreelancer/llama.cpp-rpc
Other:
-
https://github.com/ggerganov/ggml/pull/761
-
https://github.com/ggerganov/llama.cpp/issues/7293
-
https://github.com/ggerganov/llama.cpp/pull/6829
-
https://github.com/ggerganov/llama.cpp/tree/master/examples/rpc
-
https://github.com/mudler/LocalAI/commit/fdb45153fed10d8a2c775633e952fdf02de60461
-
https://github.com/mudler/LocalAI/pull/2324
-
https://github.com/ollama/ollama/issues/4643
-
https://github.com/ollama/ollama/pull/6729









Write comment