- AI
- A
Personal AI assistant on your data. Part 1: Vector Database ChromaDB + DeepSeek | GPT
Today we’ll talk about a topic that sparks lively interest among many developers and AI enthusiasts — integrating large language models like DeepSeek or ChatGPT with your own knowledge base.
Friends, hello! Today I would like to discuss a topic of interest to many, namely the integration of a large language model like DeepSeek or ChatGPT with your own knowledge base.
In this article, I will give you a detailed explanation of how vector databases work and why they can be useful when integrating your knowledge base with ready-made "big" neural networks.
As an example, let’s consider the search in the documentation of Amvera Cloud — a cloud platform with built-in proxying to OpenAI, Gemini, Claude, Grok, as well as the ability to update projects via git push.
We are actively developing an AI agent that will help users deploy projects in the cloud, debug code and configuration errors, and simplify working with documentation. And the search in the documentation is a perfect case for applying a vector database, such as Chroma.
Let’s immediately address a limiting block
Ready-made neural networks, such as DeepSeek, ChatGPT, or Claude, are initially designed to process textual data with a specific context (prompt) as input, and then, based on their parameters and training, they will process your request and perform the necessary task.
That is, considering that we will be working with ready-made language models, we cannot avoid the process of preparing prompts with a specific context and sending requests to the neural networks.
This leads to a logical task — how do we tie our database to the process of interacting with the neural network? Let’s imagine this is thousands of pages of professional literature. It’s doubtful that we will form hundreds of megabytes of data into one giant prompt and expect the neural network to work with it. At the very least, we will get an error saying that the provided context is too large.
It makes sense to formulate the solution of creating a query by supplementing it only with the necessary context for that particular request, but how can we do this? The simplest option would be to organize a sort of SEO search engine. We send, for example, “neural network training” and search through our gigabytes of data, but here a logical problem arises. Even if we find information, let’s say 1000 occurrences of the phrase “neural network training,” how do we highlight this context? How do we decide what is important to pass to the neural network for communication and what is not?
Of course, we could get very detailed with the search engine, but, as you understand, this approach isn’t optimal, which means we need to look for another, more flexible and successful solution, which we will discuss in detail today.
Vector databases
I know that, most likely, you either haven’t heard of such databases or you are only superficially familiar with them. So, next, I will explain in detail, in simple terms, what these databases are and, most importantly, we will figure out how they can help us in our task.
In short and simple terms, a vector database is a representation of data: textual or byte data in numerical form, or more precisely, in the form of vectors.
For example, the word “hello” in vector form will look like this [-0.012, 0.124, -0.056, 0.203, ..., 0.078] (I’ve removed unnecessary digits for clarity).
In today's context, the mathematical method by which these numbers are derived doesn't matter much. What's important now is just a general understanding of the digital representation of data.
Practical Use
At this stage, you might logically ask: "This is all fun and very interesting, but what is the practical benefit of it, and how do we get these strange numbers?" Let's figure it out.
The first thing to understand is that neural networks cannot read your texts or look at your photos in the common human sense. For example, when sending a query to ChatGPT, the following happens:
The neural network receives the text.
It transforms this text into vectors, or more accurately, embeddings.
It uses these embeddings to generate a response based on the trained parameters of the model.
It performs calculations.
It gets the response in the form of an embedding.
It transforms the embedding back into human-readable text (Natural Language).
It sends you the human-readable text.
So, even at this stage, it's clear that when interacting with neural networks, there is something like the numerical representation of incoming information (representation in the form of embeddings), and now let's figure out why this is necessary.
Embeddings and Why They Are Needed
Embeddings are "digital fingerprints of meaning" in text. Let's break down this statement with a real example.
Imagine you have a huge pile of documents — books, articles, notes. And you want to find information in them not by exact words, but by meaning.
How to Implement It:
The neural network takes all the words you've prepared and converts them all into sequences of numbers (embeddings).
Example:
"Cat" → [0.2, -0.5, 0.7, ...]
"Kitten" → [0.19, -0.48, 0.69, ...] (almost the same numbers, because the meanings are close!).
A vector database, like Chroma, stores these numbers and can:
Search for vectors with similar meanings (even if the words are different).
Answer queries like: "Find something about furry pets" → it will return documents about cats, kittens, etc.
Simple Analogy:
Regular search (like Ctrl+F): looks for exact word matches.
A query for "car" won't find "vehicle".
Search by embeddings: looks for similar meanings.
"Car", "vehicle", "transport" — will be close in numbers, and the database will link them.
Why Is This Needed?
Chatbots (like ChatGPT) use embeddings to understand queries by meaning, not exact matches.
You can ask a document in your own words, and the system will understand, even if there are no exact matches.
Result: Embeddings are a "translator" of text into numbers, enabling searches by meaning, not by letters. Vector databases are their "storage," where search works like a magnet for similar ideas.
There are special neural networks that can transform your text data into vector (numerical) representations. For such tasks, it's not necessary to use giants like ChatGPT or DeepSeek; specialized neural networks will suffice. In the practical part, I will demonstrate creating embeddings and implementing smart search using the paraphrase-multilingual-MiniLM-L12-v2 neural network.
This neural network weighs only 500 MB, and it runs locally even on average computers, so it is ideal for our tasks.
Vector Databases (continuation)
By this point, you should understand that when working with data in numerical representation, the following link applies:
Text data is transformed into vector (numerical) representation using a special neural network. Then, in order for the smart search to work, we need to:
Obtain the embedding of your data array in vector representation.
Write a text query like "find everything worn on the hand".
Transform the query into a vector representation.
Compare the query vector with the vectors from the large embedding.
Transform the found result back into human speech.
Provide the result.
Now a logical question arises about storing these numerical data. It's clear, we can take text, then turn it into vectors using some, as yet unclear, paraphrase-multilingual-MiniLM-L12-v2, but what about storage?
It can be stored in a specialized database, like Chroma, with which we will work today, or in RAM.
Memory Storage Principle:
Prepare text data.
Transform them into embeddings.
Send a query to the embedding.
After the script finishes, the memory is cleared, and when you access it again, there is a need to regenerate the embedding.
Specialized Database Storage Principle:
Prepare text data.
Transform them into embeddings.
Save the embedding in database format.
When working, connect to the database and use the prepared embedding.
Vector databases can be both local (Self-hosted solutions) and cloud-based.
The simplest local database is ChromaDB, with which we will work today. I chose it for its simplicity and very good integration with the Python programming language.
Other local vector databases: Qdrant, Weaviate, Milvus, and others.
Here are a few examples of cloud databases: Pinecone, RedisVL, Qdrant Cloud, and others.
What will we do today?
There will still be theory, but I am sure you are waiting for the practical part. So let's figure out what we will practically do, apart from absorbing theoretical information.
Next, I will show you with a practical example how to transform text data into the ChromaDB vector database. We will first create a database with a simple example and work with search on it, and then we will work with a more complex example, based on which we will create our smart assistant later.
After we fully understand how the embedding generation and smart search inside them work — we will connect large neural networks DeepSeek and GPT to the general context, implementing the following logic:
The user sends a specific query.
We, using smart search, retrieve additional content from our vector database.
The user query, along with our "smart output", is forwarded to DeepSeek / GPT, and we get the response from the neural network based on our personal context.
It will be interesting!
Simple Vector Database
Now, to reinforce the general theoretical block described above, we will create a simple ChromaDB database based on the product descriptions of a fictional online store (for a basic example, this is a clear illustration).
Imagine that we have an array of products like this:
SHOP_DATA = [
{
"text": 'Lenovo IdeaPad 5 laptop: 16 GB RAM, 512 GB SSD, 15.6" screen, price 55$0.00.',
"metadata": {
"id": "1",
"type": "product",
"category": "laptops",
"price": 55000,
"stock": 3,
},
},
{
"text": "Xiaomi Redmi Note 12 smartphone: 128 GB, 108 MP camera, price 18$0.00.",
"metadata": {
"id": "2",
"type": "product",
"category": "phones",
"price": 18000,
"stock": 10,
},
},
# ... and so on
]
As you can see, the information is presented in the form of a list of dictionaries, each containing 2 main keys: text and metadata.
Documents and metadata in vector databases
This is an important point that deserves more attention. You need to understand that in the ChromaDB database, our entire "smart" search will work "out of the box" only on the value of the key text (the name can be anything).
In the context of vector databases, there are concepts such as documents (in our case, this is the text describing a specific product) and metadata.
Document length limitations
At the stage of preparing textual data for loading into the vector database, it is extremely important to take into account the length restrictions imposed by the model that will convert it into a vector representation. These restrictions depend on the specific neural network and usually range from 256 to 512 tokens.
Thus, if, for example, you plan to add a full book of 200 pages to the database, it must first be broken into smaller fragments — each no longer than 256–512 tokens. This will ensure correct processing of the text by the model and preserve its semantic integrity in the vector space.
The paraphrase-multilingual-MiniLM-L12-v2 model, with which we will work today, has a 512-token limit per document. This is about 250–350 words or 1500–2200 characters. However, considering that we will use our data together with powerful neural networks like Deepseek and ChatGPT, we will make the document size smaller to avoid overloading the context.
The role of metadata
Metadata are our helpers that make the search more accurate and localized. Here's a simple example:
Imagine that your online store sells laptops, smartphones, and other electronics. You can limit the smart search by metadata of category (category). Whether you use metadata for search explicitly or not, it is important to understand that the found documents (search results) will always contain these meta-tags, which will allow you to perform additional processing.
Example with books:
Imagine that you decided to upload the entire Harry Potter book series into the vector database. You split the entire text into fragments of 512 tokens, and as meta-tags, you included: the book title, page number, chapter number, and other information.
Next, you send a query like “When did Harry Potter learn about the Horcruxes?” Your smart search returns a specific number of results — documents with meta-tags that allow you to understand which book and which page the information is from.
Another example of working with metatags is restricting the search to a specific book, series of books, or author when forming a query.
At the same time, note that smart search is not related to metadata in any way unless you explicitly specify the logic for processing them in the query.
Practical application of metadata
In the context of metadata for our products:
{
"id": "1",
"type": "product",
"category": "laptops",
"price": 55000,
"stock": 3,
}
We pass the product ID, type, category, price, and stock. For example, on the website, you could implement smart search for products and display only those products with the found ID on the results page for the user.
Thus, a vector database is an excellent tool not only for integration with neural networks but also for solving practical tasks such as a smart search engine on your website or in your API.
Creating a vector database in Python
Now let's write some code. The code will be simple since we don't need to split documents (product descriptions) into fragments or perform additional logic for parsing and processing products.
Project preparation
The first thing we do is create a new Python project with a dedicated virtual environment. Add a requirements.txt file to the project with the following content:
langchain-huggingface==0.1.2
torch==2.6.0
loguru==0.7.3
chromadb==0.6.3
sentence-transformers==3.4.1
langchain-chroma==0.2.2
pydantic-settings==2.8.1
langchain-text-splitters==0.3.7
langchain-deepseek==0.1.3
langchain-openai==0.3.11What is langchain?
You may have noticed that the word langchain appears five times in my dependencies, which is not accidental.
Langchain is a powerful Python tool that "out of the box" lets you integrate a huge number of neural networks and other useful tools into your project. This framework deserves mention in more than one article, so I strongly recommend checking the project documentation (105k+ stars on GitHub should hint that the project is worth paying attention to).
In today's project, we will be using the following tools from this framework:
langchain-text-splitters==0.3.7
A tool for splitting large texts into smaller fragments (chunks). It contains various segmentation strategies: by characters, sentences, tokens, semantic blocks. Required for processing large documents when they exceed the language model's context window (256–512 tokens in our case).
langchain-deepseek==0.1.3
Integration with DeepSeek AI models. Allows you to use powerful DeepSeek language models for text analysis and generation (today's demonstration will be based on the deepseek-chat model).
langchain-openai==0.3.11
Adapter for working with the OpenAI API. Provides access to the GPT family of language models and their functions. Includes support for chat models, embedding models, and utilities for working with images via DALL-E (we'll look at an example with the gpt-3.5-turbo model).
langchain-chroma==0.2.2
Connector for the ChromaDB vector database. Enables efficient storage and retrieval of vector representations of texts for semantic search functionality and building knowledge bases with similarity search.
langchain-huggingface==0.1.2
--- Unlock smart search with Langchain and ChromaDB – boost your Python projects today! [Learn more](https://github.com/langchain-ai/langchain)Integration with the Hugging Face ecosystem provides access to thousands of open-source models developed by the community. These include language models, models for embeddings, classification, and other NLP tasks. This tool is especially useful when you need to run models locally or use specialized models. In our case, we will be able to use the local neural network paraphrase-multilingual-MiniLM-L12-v2.
Other packages
torch: The machine learning library powering many language models
loguru: A convenient logger for tracking the execution of our code
chromadb: The vector database itself, which we will use
sentence-transformers: A library for converting text into vectors (embeddings)
Dependency installation
Now, let's run the installation:
pip install -r requirements.txt
The installation may take a considerable amount of time due to the overall size of the packages (in my case, the installation process took about 20 minutes).
Database creation
Now let's create a file named create_chromadb.py (you can give it any name).
Let's do the imports:
import time
from langchain_huggingface import HuggingFaceEmbeddings
import torch
from loguru import logger
from langchain_chroma import Chroma
Let’s define the main variables:
CHROMA_PATH = "./shop_chroma_db"
COLLECTION_NAME = "shop_data"
Collections in vector databases can be thought of as tables in classic databases. If you don't specify a collection name, ChromaDB will use a default value.
Now let’s add a product array (the more the better):
SHOP_DATA = [
{
"text": 'Laptop Lenovo IdeaPad 5: 16 GB RAM, 512 GB SSD, 15.6" screen, price 55$0.00.',
"metadata": {
"id": "1",
"type": "product",
"category": "laptops",
"price": 55000,
"stock": 3,
},
},
# Add the remaining products here
]
And finally, let's write a function to create the database:
def generate_chroma_db():
try:
start_time = time.time()
logger.info("Loading embedding model...")
embeddings = HuggingFaceEmbeddings(
model_name="sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2",
model_kwargs={"device": "cuda" if torch.cuda.is_available() else "cpu"},
encode_kwargs={"normalize_embeddings": True},
)
logger.info(f"Model loaded in {time.time() - start_time:.2f} sec")
logger.info("Creating Chroma DB...")
chroma_db = Chroma.from_texts(
texts=[item["text"] for item in SHOP_DATA],
embedding=embeddings,
ids=[str(item["metadata"]["id"]) for item in SHOP_DATA],
metadatas=[item["metadata"] for item in SHOP_DATA],
persist_directory=CHROMA_PATH,
collection_name=COLLECTION_NAME,
)
logger.info(f"Chroma DB created in {time.time() - start_time:.2f} sec")
return chroma_db
except Exception as e:
logger.error(f"Error: {e}")
raise
In this code, we:
Create a model for converting text into vectors (embeddings)
Initialize the Chroma database with our products
Pass in texts, IDs, metadata, and search space settings
Log successful creation or errors
It should be noted that we use the multilingual model paraphrase-multilingual-MiniLM-L12-v2, which works well with Russian. This allows us to correctly create vector representations for our products in Russian. The model itself will be downloaded automatically from the Hugging Face repository the first time it’s launched. For subsequent runs, if the model is already on your machine, downloading won’t be necessary.
The main feature of the chosen model is that it is balanced in terms of size and quality—it provides good text vectorization results even on a CPU, but works significantly faster with a CUDA-compatible graphics card. Additionally, thanks to the normalize_embeddings=True parameter, all created embeddings will be normalized, which improves the accuracy of finding similar products.
Run the code:
if __name__ == "__main__":
generate_chroma_db()
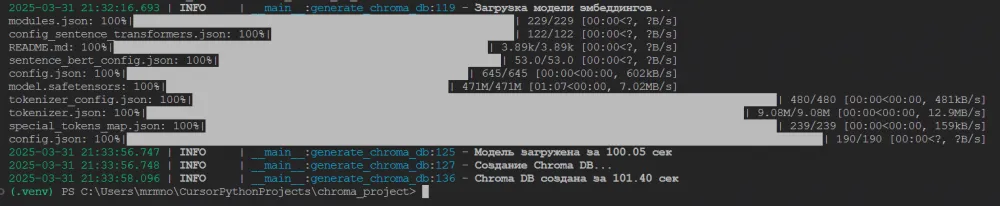
Done! Now we have a foundation for creating a vector database with descriptions from documents. After running, a folder named "shop_chroma_db" should appear in the project root, containing the database files. Later, we can use this database for semantic product search by user queries—the search will find not only exact matches but also semantically similar products.
Creating a search engine for the database
Now that the database is ready, we can describe a simple search system within its framework. The principle here will be as follows:
Connect to the existing database and get the embeddings
Accept the search query from the user
Transform the search query into a vector representation
Compare the resulting query vector with the data in the database
Return to the user the number of documents requested
Regarding document delivery to the user, there is a feature: you always specify how many documents you want to receive. For example, it can be five. If you don’t strictly tie to metadata with filters, you will always receive exactly the number of documents you requested from the database as a response.
This means that even if the results don’t match your query at all, you’ll still get your five documents as a response. That’s something to consider when designing the user interface.
The response itself consists of the document, its associated metadata, and the ranking index (the lower this index, the more similar the document is in meaning). The results are ordered by: the lower the index, the higher the position in the output.
Now, back to the code.
Imports:
from langchain_huggingface import HuggingFaceEmbeddings
import torch
from loguru import logger
from langchain_chroma import Chroma
Variables:
CHROMA_PATH = "./shop_chroma_db"
COLLECTION_NAME = "shop_data"
Now let’s describe the function for connecting to an existing database:
def connect_to_chroma():
"""Connect to an existing Chroma database."""
try:
logger.info("Loading embedding model...")
embeddings = HuggingFaceEmbeddings(
model_name="sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2",
model_kwargs={"device": "cuda" if torch.cuda.is_available() else "cpu"},
encode_kwargs={"normalize_embeddings": True},
)
chroma_db = Chroma(
persist_directory=CHROMA_PATH,
embedding_function=embeddings,
collection_name=COLLECTION_NAME,
)
logger.success("Successfully connected to Chroma database")
return chroma_db
except Exception as e:
logger.error(f"Error connecting to Chroma: {e}")
raise
This function returns a database object that’s ready to use, within which vector search will be performed.
Now let's describe a function that will allow us to search both the document (documentation pages) and metadata:
def search_products(query: str, metadata_filter: dict = None, k: int = 4):
"""
Search pages by query and metadata.
Args:
query (str): Text query for searching
metadata_filter (dict): Optional metadata filter
k (int): Number of results to return
Returns:
list: List of found documents with their metadata
"""
try:
chroma_db = connect_to_chroma()
results = chroma_db.similarity_search_with_score(
query, k=k, filter=metadata_filter
)
logger.info(f"Found {len(results)} results for query: {query}")
formatted_results = []
for doc, score in results:
formatted_results.append(
{
"text": doc.page_content,
"metadata": doc.metadata,
"similarity_score": score,
}
)
return formatted_results
except Exception as e:
logger.error(f"Error during search: {e}")
raise
And now let's call it:
for i in search_products(query="how to deploy an app in Amvera using git push?"):
print(i)
The metadata_filter parameter allows us to specify filtering conditions based on metadata. Here, an example of searching for products in an online store fits better than our documentation. For example, if we want to find only laptops with a price less than 60$0.00, we can use a filter like this:
filter_condition = {
"category": "laptops",
"price": {"$lt": 60000}
}
Here, I want to note that this example is educational. In a production system, a class is usually created to manage the database session so that you can connect once and maintain the connection. In the current implementation, every function call will restart the connection and load the embedding model, which is quite resource-intensive. In the next article, if I see that you're interested in this topic, I will show you how to implement such a class and how a full-fledged web application can be built using a vector database.
By the way, the source code of today's project, as well as the already written class for managing the connection to the vector database, can be found in my Telegram channel "Easy Path in Python". The full source code of the project has been available there for about a week.
Let's call the search and look at the results.
Not bad, right? Even though we didn't explicitly specify a specific model of vacuum cleaner or its characteristics in the query, the vector search was able to understand the semantics of the request and return the most relevant results from our database. This demonstrates the power of vector databases combined with modern language models.
Let's get to practice
Now that you understand the basic principles of working with vector databases, we can move on to creating more complex logic.
This will be about the Amvera Cloud service, which I have mentioned multiple times in my previous articles on tekkix. In short, it is a platform for simple deployment (remote execution) of projects in practically any programming language.
One of the nice advantages of Amvera Cloud is the ability to quickly deploy a project using various technologies, either via git push (or by dragging files directly into the interface), as well as getting a free domain name for it. Additionally, the service provides free built-in proxying to the OpenAI, Antropic, Cloude, and Grok APIs, which is convenient for interacting with LLMs. Thanks to these technical capabilities, the service has extensive and detailed documentation for any occasion: from basic guides like migrating from Heroku to more specific topics—such as running projects on FastAPI or Django, or addressing billing-related questions.
This documentation (around 70 different documents) is perfect for a practical demonstration: we can take a set of texts, turn it into a vector database, and show how to effectively integrate such a database with neural models to get meaningful and useful answers.
Input data
I already had about 70 Markdown documents from Amvera in this format:
# Support for Kubernetes Probes
## How to set up?
You need to fill out the settings in YAML format, native to the k8s format itself (see [here](https://kubernetes.io/docs/tasks/configure-pod-container/configure-liveness-readiness-startup-probes/)). The configuration file is inserted into your Deployment, which is loaded into the cluster with it.
This means, if you upload a non-working setting or in the wrong format, your project will fail at the build stage. ...
These documents were given to me as a project, containing both md files and various other technical files. But most likely, you won’t be so lucky.
So keep in mind that to collect information for the database you can use any tools that suit you: website parsing, loading data from your own SQL databases, reading documents in Excel, Word, PDF formats, and so on. The main thing is that in the end the data is converted into a format that vector databases support and has a clear structure.
The first thing I did as part of the preparation was decide to transform all these files with nested structure into JSON format like this:
{
"text": "backups backups data eval rst admonition important and so on throughout the text",
"metadata": {
"section_count": 2,
"section_1": "Backups",
"section_2": "Backups /data"
}
}
This means it’s full text information under the text key, without punctuation, special symbols or caps, and technical information such as the number and names of sections, etc., is placed in metadata.
The key point here is that metadata is helpful, but you could just use the texts alone. Still, with metadata we get extra opportunities for filtering and analysis of search results.
Let’s describe the logic for creating a folder with JSON files:
Imports
import json
import os
import re
import string
import sys
from typing import Any, Dict, List
from config import settings
from loguru import logger
Here I used Python's built-in libraries, except for loguru—which is for convenient logging of results. The extraction itself will focus on regular expressions.
Let's output the constants:
HEADER_PATTERN = re.compile(r"^(#+)\s(.+)")
PUNCTUATION_PATTERN = re.compile(f"[{re.escape(string.punctuation)}]")
WHITESPACE_PATTERN = re.compile(r"\s+")
Let’s describe the logic for text normalization:
def normalize_text(text: str) -> str:
"""Text normalization: removing punctuation marks and special characters."""
if not isinstance(text, str):
raise ValueError("Input text must be a string")
# Remove punctuation
text = PUNCTUATION_PATTERN.sub(" ", text)
# Remove line breaks and extra spaces
text = WHITESPACE_PATTERN.sub(" ", text)
# Convert to lowercase
return text.lower().strip()
Let’s write the logic for parsing a single markdown file:
def parse_markdown(md_path: str) -> Dict[str, Any]:
"""Parse a markdown file and create structured data."""
if not os.path.exists(md_path):
raise FileNotFoundError(f"File {md_path} not found")
try:
with open(md_path, "r", encoding="utf-8") as file:
content = file.read()
except Exception as e:
logger.error(f"Error reading file {md_path}: {e}")
raise
sections: List[str] = []
section_titles: List[str] = []
current_section: str | None = None
current_content: List[str] = []
for line in content.splitlines():
section_match = HEADER_PATTERN.match(line)
if section_match:
if current_section:
sections.append("\n".join(current_content).strip())
section_titles.append(current_section)
current_content = []
current_section = section_match.group(2)
current_content.append(current_section)
else:
current_content.append(line)
if current_section:
sections.append("\n".join(current_content).strip())
section_titles.append(current_section)
# Text normalization for the vector database
normalized_sections = [normalize_text(section) for section in sections]
full_text = " ".join(normalized_sections)
# Create metadata structure
metadata = {
"file_name": os.path.basename(md_path),
"section_count": len(section_titles),
}
# Add titles as separate fields
for i, title in enumerate(section_titles):
metadata[f"section_{i+1}"] = title
return {"text": full_text, "metadata": metadata}
And let’s describe the function to parse all documents:
def process_all_markdown(input_folder: str, output_folder: str) -> None:
"""Process all markdown files in the directory."""
if not os.path.exists(input_folder):
raise FileNotFoundError(f"Input directory {input_folder} not found")
try:
os.makedirs(output_folder, exist_ok=True)
except Exception as e:
logger.error(f"Error creating output directory: {e}")
raise
for root, _, files in os.walk(input_folder):
for file_name in files:
if file_name.endswith(".md"):
try:
md_path = os.path.join(root, file_name)
output_path = os.path.join(
output_folder, file_name.replace(".md", ".json")
)
parsed_data = parse_markdown(md_path)
with open(output_path, "w", encoding="utf-8") as file:
json.dump(parsed_data, file, ensure_ascii=False, indent=4)
logger.info(f"Result saved to {output_path}")
except Exception as e:
logger.error(f"Error processing file {file_name}: {e}")
The input to the function is a folder containing all the documents, and a folder in which the resulting JSON files will be written.
The logic for detecting md files works so that it searches through all nested folders in the documents directory. This is especially useful if your documentation has a complex file and directory structure.
Now call it:
if __name__ == "__main__":
try:
process_all_markdown(
input_folder="path to the folder with documents",
output_folder="path to the folder for saving JSON",
)
except Exception as e:
logger.error(f"Critical error: {e}")
sys.exit(1)
Run.
The files are ready! Now all that's left is to read all the files and, based on them, create a vector database.
Note that our parser extracts not only text from Markdown but also the document structure. In the metadata, we store the file name and the headers of all sections. This allows us not only to search by content but also to precisely indicate from which section of the documentation any particular fragment was taken, which is very useful for creating meaningful assistant responses.
Creating the database
The process of creating a database for Amvera is not much different from the previously described approach, with the exception that the data will be taken from existing JSON files.
Before continuing, for more structured code, let's create a .env file in the root of the project and put the following variables inside:
DEEPSEEK_API_KEY=sk-1234
OPENAI_API_KEY=sk-proj-1234
Both API keys should be here. If the keys are missing, you can skip creating the file.
Next, create a file config.py and fill it as follows:
import os
from pydantic import SecretStr
from pydantic_settings import BaseSettings, SettingsConfigDict
class Config(BaseSettings):
DEEPSEEK_API_KEY: SecretStr
BASE_DIR: str = os.path.abspath(os.path.join(os.path.dirname(__file__)))
DOCS_AMVERA_PATH: str = os.path.join(BASE_DIR, "amvera_data", "docs_amvera")
PARSED_JSON_PATH: str = os.path.join(BASE_DIR, "amvera_data", "parsed_json")
AMVERA_CHROMA_PATH: str = os.path.join(BASE_DIR, "amvera_data", "chroma_db")
AMVERA_COLLECTION_NAME: str = "amvera_docs"
MAX_CHUNK_SIZE: int = 512
CHUNK_OVERLAP: int = 50
LM_MODEL_NAME: str = "sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2"
DEEPSEEK_MODEL_NAME: str = "deepseek-chat"
OPENAI_MODEL_NAME: str = "gpt-3.5-turbo"
OPENAI_API_KEY: SecretStr
model_config = SettingsConfigDict(env_file=f"{BASE_DIR}/.env")
settings = Config() # type: ignore
In this class, we collect all the necessary variables for working on the project. As you can see, here are specified the paths to important folders (your structure may be different), collection names, maximum chunk size, and neural network model names.
Pay particular attention to the API key declarations:
OPENAI_API_KEY: SecretStr
DEEPSEEK_API_KEY: SecretStr
It's important to declare them not as ordinary strings, but specifically as SecretStr. This is a requirement of the LangChain library for secure handling of confidential data.
Now we can import the settings variable anywhere in the code and access the required settings via dot notation.
Creating the database
Let's get back to creating the database. We'll start with imports:
import json
import os
import sys
from typing import Any, Dict, List, Optional
import torch
from langchain_chroma import Chroma
from langchain_huggingface import HuggingFaceEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
from loguru import logger
from config import settings
Here, among other things, you see the import of RecursiveCharacterTextSplitter. This component will allow us to break up large documents into semantic chunks (text fragments that are logically connected).
Let's write a function to load all existing JSON files into a list of dictionaries:
def load_json_files(directory: str) -> List[Dict[str, Any:
"""Load all JSON files from the specified directory."""
documents = []
try:
if not os.path.exists(directory):
logger.error(f"Directory {directory} does not exist")
return documents
for filename in os.listdir(directory):
if filename.endswith(".json"):
file_path = os.path.join(directory, filename)
try:
with open(file_path, "r", encoding="utf-8") as file:
data = json.load(file)
documents.append(
{"text": data["text"], "metadata": data["metadata"]}
)
logger.info(f"File loaded: {filename}")
except Exception as e:
logger.error(f"Error reading file {filename}: {e}")
logger.success(f"{len(documents)} JSON files loaded")
return documents
except Exception as e:
logger.error(f"Error loading JSON files: {e}")
return documents
After executing this function, we get all the data from JSON files as dictionaries stored in RAM. The information from these dictionaries can then be used to create a vector database.
Now let's describe the logic for splitting large documents into semantic chunks:
def split_text_into_chunks(text: str, metadata: Dict[str, Any]) -> List[Any]:
"""Split text into chunks while preserving metadata."""
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=settings.MAX_CHUNK_SIZE,
chunk_overlap=settings.CHUNK_OVERLAP,
length_function=len,
is_separator_regex=False,
)
chunks = text_splitter.create_documents(texts=[text], metadatas=[metadata])
return chunks
As a result, we still have a list of dictionaries, but now large texts are split into semantic chunks. Each chunk contains the necessary metadata. This is helpful for preserving overall context even when breaking a large text into many pieces.
Finally, let's describe the logic for creating a vector database:
def generate_chroma_db() -> Optional[Chroma]:
"""Initialize ChromaDB with data from JSON files."""
try:
# Create a directory to store the database if it doesn’t exist
os.makedirs(settings.AMVERA_CHROMA_PATH, exist_ok=True)
# Load JSON files
documents = load_json_files(settings.PARSED_JSON_PATH)
if not documents:
logger.warning("No documents to add to the database")
return None
# Initialize embeddings model
embeddings = HuggingFaceEmbeddings(
model_name=settings.LM_MODEL_NAME,
model_kwargs={"device": "cuda" if torch.cuda.is_available() else "cpu"},
encode_kwargs={"normalize_embeddings": True},
)
# Prepare data for Chroma
all_chunks = []
for i, doc in enumerate(documents):
chunks = split_text_into_chunks(doc["text"], doc["metadata"])
all_chunks.extend(chunks)
logger.info(
f"Document {i+1}/{len(documents)} split into {len(chunks)} chunks"
)
# Create the vector storage
texts = [chunk.page_content for chunk in all_chunks]
metadatas = [chunk.metadata for chunk in all_chunks]
ids = [f"doc_{i}" for i in range(len(all_chunks))]
chroma_db = Chroma.from_texts(
texts=texts,
embedding=embeddings,
ids=ids,
metadatas=metadatas,
persist_directory=settings.AMVERA_CHROMA_PATH,
collection_name=settings.AMVERA_COLLECTION_NAME,
collection_metadata={
"hnsw:space": "cosine",
},
)
logger.success(
f"Chroma database initialized, {len(all_chunks)} chunks from {len(documents)} documents added"
)
return chroma_db
except Exception as e:
logger.error(f"Chroma initialization error: {e}")
raise
The logic for creating the database isn’t much different from examples discussed earlier. The main difference is the splitting of long texts into meaningful chunks.
On my rather modest computer, the process of creating the database took less than 10 minutes. On devices with a GPU, this process takes only a few minutes thanks to parallel computations.
Performance Optimization
Note that when working with large volumes of data, the process can be further optimized:
Use batching when creating embeddings (processing documents in groups)
Adjust the MAX_CHUNK_SIZE and CHUNK_OVERLAP parameters depending on your data structure
Choose an appropriate embedding model, balancing quality and speed
ChromaDB delivers solid performance for most RAG tasks, but for very large volumes of data (millions of documents), you may want to consider other solutions, such as FAISS or Pinecone.
Integrating the Search Engine with Neural Networks
Earlier, we discussed how to describe a search engine without using large neural networks. To reinforce this material, I suggest you independently create such a search engine based on your database.
Now I’ll move on to the most interesting part—explaining how to combine results from a vector database with neural networks to create a smart AI agent. For this, we’ll use data from Amvera Cloud documentation, which I’ve already transformed into a vector database.
Initial Project Setup
Let's start by creating a file named chat_with_ai.py.
Let's perform the necessary imports:
from typing import Any, Dict, List, Literal, Optional
import torch
from config import settings
from langchain_chroma import Chroma
from langchain_deepseek import ChatDeepSeek
from langchain_openai import ChatOpenAI
from langchain_huggingface import HuggingFaceEmbeddings
from loguru import logger
Here we connect new tools langchain_deepseek and langchain_openai, which let us easily integrate DeepSeek and ChatGPT models (as well as other OpenAI models) into our project.
Main Class Structure
For more structured code, I decided to organize it as a class. Let's declare our class and describe its initialization logic:
class ChatWithAI:
def __init__(self, provider: Literal["deepseek", "openai"] = "deepseek"):
self.provider = provider
self.embeddings = HuggingFaceEmbeddings(
model_name=settings.LM_MODEL_NAME,
model_kwargs={"device": "cuda" if torch.cuda.is_available() else "cpu"},
encode_kwargs={"normalize_embeddings": True},
)
if provider == "deepseek":
self.llm = ChatDeepSeek(
api_key=settings.DEEPSEEK_API_KEY,
model=settings.DEEPSEEK_MODEL_NAME,
temperature=0.7,
)
elif provider == "openai":
self.llm = ChatOpenAI(
api_key=settings.OPENAI_API_KEY,
model=settings.OPENAI_MODEL_NAME,
temperature=0.7,
)
else:
raise ValueError(f"Unsupported provider: {provider}")
self.chroma_db = Chroma(
persist_directory=settings.AMVERA_CHROMA_PATH,
embedding_function=self.embeddings,
collection_name=settings.AMVERA_COLLECTION_NAME,
)
When creating a class object, we pass the provider parameter with a value of "deepseek" or "openai" to specify which neural network we’ll use in the project.
Note the following construction:
ChatDeepSeek(
api_key=settings.DEEPSEEK_API_KEY,
model=settings.DEEPSEEK_MODEL_NAME,
temperature=0.7,
)
In this simple way, we can declare the neural network we’ll be working with. It’s enough to provide the API token and model name (these are mandatory parameters). You can also pass additional parameters for more fine-tuned control, such as temperature for answer creativity control.
Getting Relevant Context
Let's describe the method for retrieving a response from the database:
def get_relevant_context(self, query: str, k: int = 3) -> List[Dict[str, Any:
"""Retrieve relevant context from the database."""
try:
results = self.chroma_db.similarity_search(query, k=k)
return [
{
"text": doc.page_content,
"metadata": doc.metadata,
}
for doc in results
]
except Exception as e:
logger.error(f"Error retrieving context: {e}")
return []
The method accepts the user's query and the number of documents we expect to retrieve (by default, it's 3 documents).
For search, I used the similarity_search method. To recap, this method transforms the search query into a vector representation and, based on this vector, searches our database.
Formatting the context
Now let's describe a method that will transform the obtained result into a format convenient for neural networks:
def format_context(self, context: List[Dict[str, Any) -> str:
"""Format the context for the prompt."""
formatted_context = []
for item in context:
metadata_str = "\n".join(f"{k}: {v}" for k, v in item["metadata"].items())
formatted_context.append(
f"Text: {item['text']}\nMetadata:\n{metadata_str}\n"
)
return "\n---\n".join(formatted_context)
This method transforms the combination of document + metadata from all retrieved documents into one structured message, which we then pass to the neural network.
Generating a response
Now let's describe a method that will link our context with the query to the neural network:
def generate_response(self, query: str) -> Optional[str]:
"""Generation of a response based on the query and context."""
try:
context = self.get_relevant_context(query)
if not context:
return "Sorry, unable to find relevant context for the response."
formatted_context = self.format_context(context)
messages = [
{
"role": "system",
"content": """You are the internal manager of Amvera Cloud (https://amvera.ru/). Respond concisely without unnecessary introductions.
Rules:
1. Get straight to the point, avoid phrases like "Based on the context"
2. Use only facts. If precise data is unavailable, respond with general phrases about Amvera Cloud, but do not fabricate specifics
3. Use plain text without formatting
4. Include links only if they are present in the context
5. Speak in the first person plural: "We provide", "We have"
6. When mentioning files, do so naturally, e.g., "I will attach the guide where the steps are described in detail"
7. Respond warmly to greetings, and with light humor to negativity
8. You can use general information from open sources about Amvera Cloud, but rely on the context
9. If the user asks about prices, plans, or technical specifications, provide specific answers from the context
10. For technical questions, offer practical solutions
Personalize the responses, mentioning the client's name if it is in the context. Be concise, informative, and helpful.""",
},
{
"role": "user",
"content": f"Question: {query}\nContext: {formatted_context}",
},
]
response = self.llm.invoke(messages)
if hasattr(response, "content"):
return str(response.content)
return str(response).strip()
except Exception as e:
logger.error(f"Error generating response: {e}")
return "An error occurred while generating the response."
Note that here we use a textual prompt that acts as a wrapper around our context. The prompt (query) can be anything, and I have provided just one possible example.
It is worth experimenting with the content of the prompt depending on the specific requirements of your project. Instructions can be more or less directive, guiding the model towards different response styles or formats of information delivery.
The method takes a user's search query as input. This query is first processed by a vector database, and based on it, we get a structured text of relevant documents. Then, this text is combined with the prepared prompt, and using the call self.llm.invoke(messages), we get a response from the neural network.
We then transform the response and return it to the user.
Running and Testing
Now, it remains to properly initialize the class and call its methods:
if __name__ == "__main__":
chat = ChatWithAI(provider="deepseek")
print("\n=== Chat with AI ===\n")
while True:
query = input("You: ")
if query.lower() == "exit":
print("\nGoodbye!")
break
print("\nAI is typing...", end="\r")
response = chat.generate_response(query)
print(" " * 20, end="\r") # Clear "AI is typing..."
print(f"AI: {response}\n")
Note that here a loop is started, which will only break if the user types "exit". This demonstrates how to maintain a connection with the Chroma vector database without having to reconnect with each query.
We connect to the database once and will disconnect from it only when our infinite loop finishes. This approach saves time on connection initialization for every user request.
Conclusion
At this stage, we have only created a prototype of the search engine for Amvera Cloud documentation — it is still difficult to call it a full-fledged service with an AI assistant.
If this material resonates with you in the form of views, likes, and comments, then in the next article, I will go into detail about which blocks of the current code can be improved. Based on the refined version, we will build a complete web service similar to the site chat.openai.com, where we will implement a full-fledged and convenient chat with our AI assistant.
I hope I managed to convey to you how vector databases work, how to collect and structure information for them, and how to organize generation and search within such databases.
Due to limited resources, I wasn't able to cover the topic in-depth and comprehensively. Therefore, I strongly recommend studying vector data representation in more detail. This is important, if only because giants like ChatGPT, Claude, DeepSeek, and other modern neural networks work specifically with vector representation of information.
Additionally, I recommend paying attention to such a powerful tool as LangChain. What we've covered in this article is just a small part of its capabilities.
Reminder: the source code of the project, including the asynchronous class for working with the ChromaDB vector database, as well as other exclusive content that I don't publish on Tekkix, can be found in my free Telegram channel «Easy Path in Python».
That's all. See you in the next article!









Write comment