
- AI
- A
Problems of personal data protection in the world of artificial intelligence
Artificial intelligence is now largely everywhere. In any industry, we are told that neural networks, machine learning, and other AI directions are used in it. Systems related to the processing of users' personal data are no exception. In this article, we will talk about how artificial intelligence and personal data protection are related.
Risks in AI data processing
The work of artificial intelligence algorithms consists of two main stages: training and usage. At the training stage, artificial intelligence algorithms are trained on special datasets, which allows them to identify patterns and relationships between different data points. At this stage, in essence, neural networks are trained to recognize the necessary entities, whether it be images in photos or text analysis.
At the usage stage, the model should already be trained and should be able to distinguish the necessary images or analyze the text in the required way.
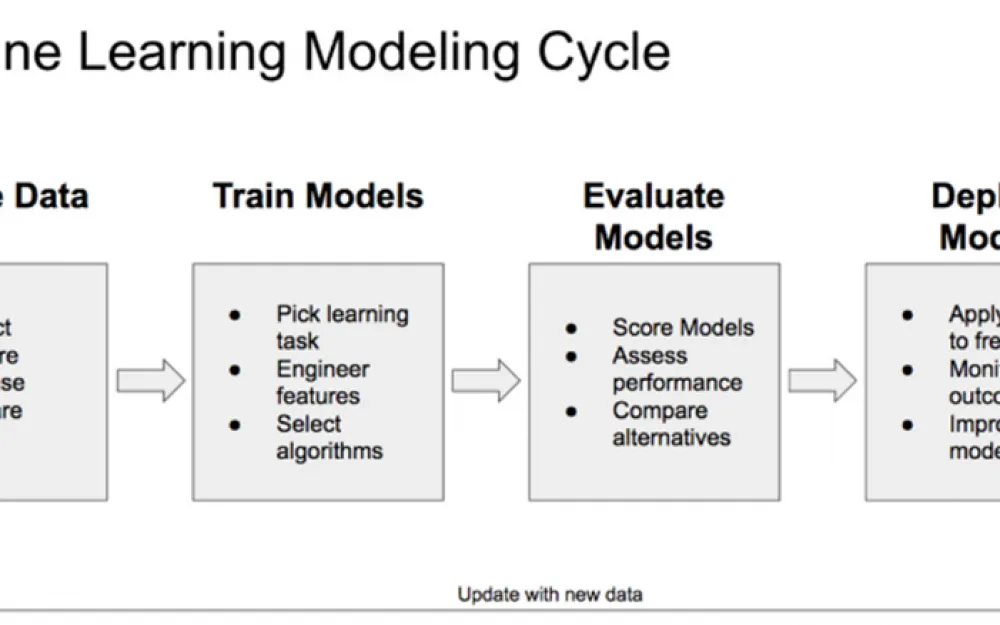
It is quite obvious that for the successful completion of both steps, the key element is data. These input data are millions of images on which the neural network is trained or thousands of pages of text.
At the same time, it is important to understand that no powerful neural network can do without "data vacuums", as truly huge amounts of data are needed for its training.
And here, questions from the field of personal data arise.
Limitations in personal data processing
Regulatory acts in the field of personal data protection impose certain requirements on the processing of personal data. We must obtain the consent of the subject for the processing of their personal data. The purposes and terms of processing must also be clearly defined. All this works well when we have some kind of application or database of clients, partners, employees, and we ensure data processing in this system.
But what to do in cases where personal data for one reason or another gets to systems using AI? The purpose limitation states that data subjects must be informed about the purposes of data collection and processing. This allows subjects to choose whether to give consent. However, machine learning systems sometimes use information that is a by-product of the original data (for example, using social media data to calculate user metrics). As a result, hidden or indirect processing of personal data becomes possible, for example, obtaining information about users of the same social networks where the neural network analyzed metrics.
A separate story is image analysis. Ideally, images, or rather photographs depicting people, should not allow the identification of these subjects without their consent. However, in practice, AI can be trained in such a way that it can quite accurately guess who is depicted in the photograph, thereby allowing the identification of personal data subjects.
Main risks
Various artificial intelligence systems use data to assess certain human qualities, such as work productivity, health status, personal preferences, and so on. For what purposes the collected data can then be used is a big question, it is quite possible that they can be used by government agencies and special services, as well as various commercial organizations, such as banks, marketing agencies, and others. And we should not discount crime. Advanced fraudsters can quite take advantage of the results of AI work if they gain access to them.
In addition, artificial intelligence systems are a black box, not only for those who use them but also for the developers themselves, who, of course, can tweak some parameters in the algorithms. But in general, the same neural networks write their algorithms during training, so how they make decisions is often a mystery even to the developers.
Also, among the risks of using AI in many, especially English-language publications, discrimination is indicated. Machine learning algorithms can build their stereotypes based on certain human traits, most often gender, race, and age. If decisions about issuing loans or hiring are automatically made based on these algorithms, this can lead to discrimination. That is, decisions are made not based on objective data, but on distorted representations, that is, initially incorrect training of the neural network.
How to protect yourself
First of all, it is necessary to minimize the amount of data being processed. When developing AI training algorithms, engineers must determine what data and in what quantity are needed to complete the task. It is important to process only the minimally necessary amount of personal data, while maximizing the anonymization of information that does not require processing as personal data.
Data subjects have the right to decide for themselves which of their data will be used by operators. This means that the operator must openly and transparently explain why they are collecting this data and what they intend to do with it. As already mentioned, artificial intelligence is a "black box," and it is not always clear how the model makes decisions, especially in complex applications.
Generative Adversarial Networks
One of the algorithms that can be used when working with personal data in ML is Generative Adversarial Networks (GAN).
Currently, there is a trend in the field of ML towards more efficient use of smaller amounts of data. GAN reduces the need for training data by using output data to generate input data. In other words, input data is used to determine what the output data will look like.
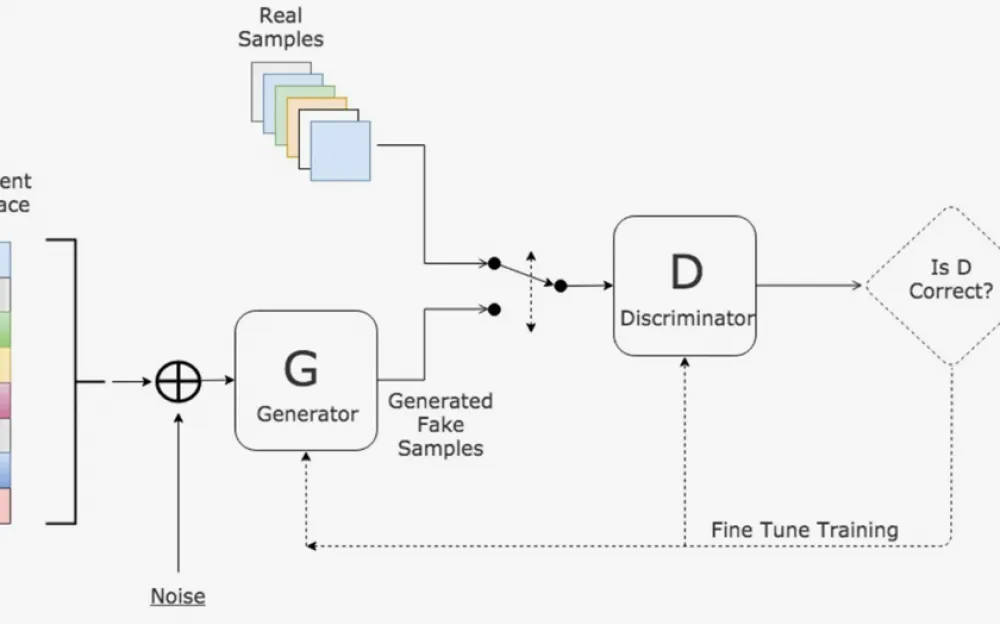
This method uses two neural networks - a "generator" and a "discriminator". The generator learns to combine data to generate an image similar to the output data, while the discriminator learns to distinguish between real data and artificially generated data. The drawback, however, is that GANs do not eliminate the need for training, as proper training requires a lot of data. However, with this method, we can reduce the amount of personal data needed for the algorithm to work.
Federated Learning
Federated learning uses personal data, but it does not actually leave the system in which it is stored. It is never collected and uploaded to the backend of AI or ML systems. Instead, the model is trained locally in the system where the data exists and later, during development, is merged with the main model.
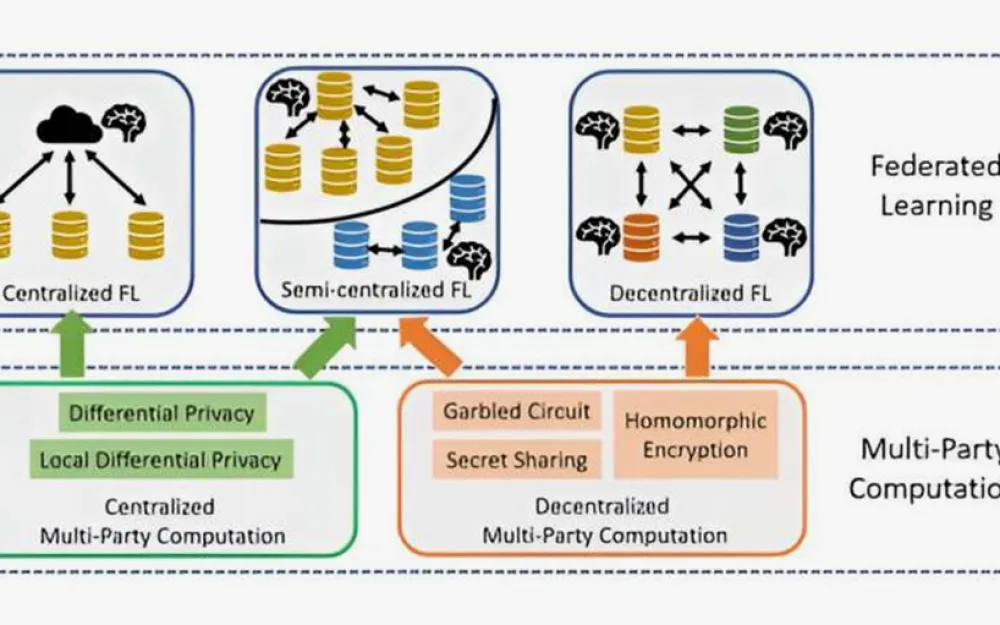
While federated learning avoids some of the issues associated with personal data, an ML model trained locally will face greater limitations than ML models trained in a dedicated system.
Conclusion
We have considered the main issues related to the use of artificial intelligence when working with personal data. Of course, some of the presented problems are inherent not only to personal data but also to any information processed by AI.
But it is important to understand that there is no perfect solution to the problems related to data protection. The presented training methods have a number of limitations that must be taken into account during design.
Continuing the topic: today (September 17) in the evening, Otus will hold an open lesson dedicated to the topic of collecting personal data in games. Participants will consider all related issues, as well as analyze real cases of violations of working with personal data in games. You can sign up for the lesson on the course page.









Write comment