
- AI
- A
Security in Machine Learning: From Design to Implementation
Polina Sokol, Senior Data Analyst at the R&D Laboratory of the Cybersecurity Technology Center of the Solar Group, prepared material on methods of working with data and ML models.
This research direction ensures transparency, accountability, and risk requirements related to artificial intelligence. It cannot be ignored when using ML in products designed to protect against targeted attacks, which themselves can become one of the targets of attackers - EDR, NTA, XDR, SIEM, and other classes of solutions.
Security in Machine Learning: Why It Is Needed
The process of developing ML models is not linear. The Crisp-DM methodology we use helps to systematize this process by dividing it into stages. However, despite the cyclicity and repeatability of these stages, there are opportunities for attacks at many of them.
Crisp-DM (Cross-Industry Standard Process for Data Mining) is a standard methodology for developing ML models and implementing them in products. It consists of the following stages:
Definition of business objectives and product vision — understanding the goals and requirements of the project;
Data acquisition and preparation — collecting, cleaning, and preprocessing data;
Model development and training — selecting algorithms and training the model on prepared data;
Model metrics evaluation — checking the quality of the model using appropriate metrics;
Model deployment preparation — optimizing and integrating the model into the product;
Gathering feedback from customers — collecting feedback for further improvement;
Reassessing the task and model metrics if necessary — adapting the model to new requirements or changes in the data.
These stages may not be sequential and can be repeated. For example, if the model metrics evaluation is unsatisfactory, it will be necessary to return to the previous step. The process is more clearly illustrated by the following diagram:

It is important to ensure security at all stages related to the development and training of the model, as problems can arise at any of them.
What needs to be protected?
Data — raw and processed data used for model training may contain confidential information;
Model — algorithms and model parameters are intellectual property and may be targets for theft or tampering;
Training pipeline — the infrastructure and processes for training and deploying the model may be vulnerable to attacks or failures.
Data Protection
Data remains a key element in ML. Insufficient data validation is one of the most common mistakes made by developers. Low-quality or compromised data can lead to serious vulnerabilities or simply errors.
It is extremely important to synchronize data work between data scientists and developers. In their work, they focus on different dataset metrics – for the former, model accuracy is important, for the latter – performance and scalability. Therefore, the R&D team "Solar" is developing a methodology for automatic testing of AI-based products to reduce the risks of vulnerabilities in ready-made solutions, ensure transparency and accountability of AI modules in software.
Another risk is leaks when using specific prompts for LLM (large language model). For example, there are currently quite a few unofficial "mirrors" of the latest large language models. An attacker may try to retrain some open model, for example, ChatGPT, to provide links to sites with exploits, malicious instructions, false information. Then he can upload this model to the network under the guise of the "original".
How do we validate data?
Malware check — we use tools such as VirusTotal to scan files for malicious code;
Quality and relevance analysis — we apply statistical methods to assess data integrity and quality;
Markup validation — manual data markup and validation.
Deep protection
Homomorphic encryption allows training a model on encrypted data without decrypting it;
Data masking helps to hide sensitive data by replacing it with dummy values;
Access control allows setting strict access rights to data and models in repositories.
Model Protection
The security of the model depends on the level of access that an attacker can obtain. There are three types:
White box: full access to the model and its internal parameters;
Black box: access only to the inputs and outputs of the model;
Gray box: partial access to the internal components of the model.
Let's consider each option in more detail. In the case of a white box, an attacker can conduct a detailed analysis of the model, identify vulnerabilities, and develop precise attacks. They can also recover the original training data and make changes to the model: change the activation function or remove a training layer. To protect against attacks at this level of access, it is necessary to control access, encrypt data, and conduct regular monitoring and auditing of the model.
If we are talking about a black box, here the attacker can interact with the model only through the user interface. The following risks are possible: they can "bombard" the model with requests and analyze the responses for patterns, or study the model's responses to create adversarial examples based on them. To prevent threats, it is worth limiting the number of requests and adding some noise to the output data to make it difficult to copy the model.
Finally, in the case of a gray box, when an attacker, for example, partially knows the internal structure of the model or knows part of the code, it is necessary first of all to prevent information leaks. All employees should be prohibited from disclosing details about the model or granting access to it. Even to colleagues.
Also, regardless of the type of access of potential attackers, it is necessary to regularly audit everything using MLFlow and use verified datasets to ensure that the model works correctly, and the results have not changed and meet expectations.
Adversarial Attacks
One of the most serious threats in ML is adversarial attacks. These are various methods by which attackers can influence machine learning models. Such attacks are aimed at distorting the results of the model or obtaining confidential information.
This is especially relevant for large language models that are capable of processing complex data and may accidentally reveal confidential information. Large language models require special protection because, unlike classical models, they can generate text based on previously processed data.
Different libraries are used to protect against such attacks: for example, Adversarial Robustness Toolbox (ART) to check the model for stability. Or Foolbox to test attacks on models and protect them. The resilience of models to vulnerabilities can be enhanced through adversarial training, where the model is trained on attack examples.
Main methods of adversarial attacks:
Evasion Attack — an attacker selects specific input data to produce the desired result: for example, confidential information. Minor changes in the image or text, imperceptible at first glance, can lead to a leak.
For example, attackers can use prompt mechanisms for the model that implement jailbreaking injections. They can "confuse" the model to obtain sensitive information.
If the LLM output is not checked for security, an attacker can use their special prompt to get the LLM to produce a response that could lead to data loss.
For example, as in the screenshot:

Data Poisoning — at the model training stage, an attacker changes the data by adding incorrectly labeled or malicious examples. As a result, the model learns on distorted data and begins to make mistakes in real use.
For example, hackers can trick a surveillance system with Face ID functionality using special glasses:

Or complicate image recognition with a special second layer:
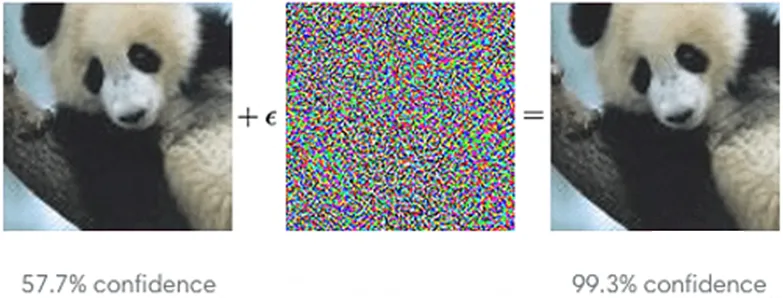
How does this affect R&D?
For example, you use a dataset from Kaggle with malware headers, and a cybercriminal added their malware to the headers and labeled them as safe files. As a result, you trained the model on them, and the model will then pass these files as safe.
How do we protect models?
Adversarial Training — we include adversarial examples in the training set so that the model learns to handle them;
Model Ensembles — we use a combination of several models, which makes it difficult to deceive the entire system;
Request Limiting and Monitoring — we control the frequency and nature of requests to the model to prevent attacks.
What do we do with open-source solutions?
Analyze the code: we conduct statistical and dynamic analysis of open-source components for vulnerabilities;
Test on our own data — before implementation, we test the model on our datasets to ensure its correct operation;
Check — we study whether third-party solutions meet our security standards.
For example, you may encounter the risk of exploiting such vulnerabilities:
Vulnerability in the TensorFlow machine learning platform (CVE-2021-41228), which allows you to execute your code when processing the attacker's data passed through the "--input_examples" parameter using the saved_model_cli utility.
The problem is caused by the use of external data when calling the code with the "eval" function. The issue is fixed in TensorFlow 2.7.0, TensorFlow 2.6.1, TensorFlow 2.5.2, and TensorFlow 2.4.4 releases.
In general, open-source solutions can and should be used in the development of ML models. However, vulnerabilities in the model's source code can give attackers access to data or even control over the model's behavior. Therefore, it is important to check such components to ensure security. For example, the SCA module in the Solar appScreener software product analyzes the open source libraries and dependencies used for vulnerabilities and reduces the risk of using vulnerable components when training ML models.
Training pipeline
For models that require regular retraining and tuning, protecting the training pipeline becomes especially important.
What risks can there be:
Attacks on new data - attackers may try to inject malicious data during retraining;
Changes in the code of data extraction, transformation, and loading (ETL) processes - unnoticed changes can lead to failures or changes in the model's behavior;
Insider threats - employees with access to the pipeline can make malicious changes.
How does this affect R&D?
An insider can change the model's code, and it will start producing worse or simply incorrect results, for example, it will mark that you do not have a blueprint scan, but just... a cat.
How to secure the pipeline?
Code and process audit — regularly check changes in the code and pipeline settings;
Access control — manage access rights to various components of the pipeline;
Monitoring and alerting — set up alert systems for unusual activity or changes in model behavior.
Load testing of models
Load testing is a critically important process in the development and operation of systems, especially when it comes to models that need to work under heavy load.
This testing allows you to evaluate the performance, stability, scalability, and stress resistance of the system, which is directly related to ensuring the smooth operation and security of AI systems. Timely load testing helps identify and eliminate potential bottlenecks in the system before they lead to failures or downtime.
For example, load testing determines how many simultaneous users or requests the system can handle without degrading performance, and also checks how the system responds to peak loads and sudden spikes in activity.
This process is also necessary for capacity planning and calculating the required technical resources.
Data obtained from load testing is used to develop Service Level Agreements (SLAs) and to compare metrics with internal benchmarks and competitor metrics. In addition, load testing helps organizations prepare for periods of growth or abnormally high levels of load, which is especially important for systems operating 24/7.
In the context of AI security, load testing provides an additional layer of protection. It helps identify and fix potential vulnerabilities that attackers might exploit, such as during DDoS attacks. At Solar R&D, we use load testing for large datasets and individual solutions for data leakage protection.
Automation of Protection and Data Analysis
Modern security systems actively use automation to detect and eliminate threats. It plays a key role in reducing the human factor and helps to find anomalies in patterns at early stages.
It is worth noting separately the work with large language models. As I mentioned earlier, one of their main features is their ability to store and randomly reproduce information they have previously received, for example, from other users.
Tools such as MLFlow allow tracking the entire model training cycle and recording changes at each stage. MLFlow is a platform for managing the ML model training cycle. It allows:
Track experiments — save model parameters, metrics, and artifacts;
Manage model versions — store different versions of models for comparison and reproducibility of results;
Control access — restrict rights to view and modify models.
Automatic tools for anomaly and threat detection:
Adversarial Robustness Toolbox (ART) — a library for generating and detecting adversarial attacks, testing model robustness. It is used for automatic detection of backdoors and anomalies in neural networks;
DNN Activation Clustering: Analyze the outputs of hidden layers of neural networks to detect anomalies. Clustering hidden layers of DNNs allows identifying datasets that contain potentially malicious data. This helps protect models from possible attacks during training.
It is worth noting separately the work with large language models. As I mentioned earlier, one of their main features is their ability to store and randomly reproduce information they have previously received, for example, from other users.
It is worth noting separately the work with large language models. As I mentioned earlier, one of their main features is their ability to store and randomly reproduce information they have previously received, for example, from other users.
Therefore, before training such models, it is important to clean the data from such elements and check their relevance. In addition, automating the data verification process using specialized tools reduces the likelihood of errors and data leaks.
Conclusions
Security in machine learning is a continuous process that requires attention at every stage of model development and deployment. The problem will become even more important as models become more complex and larger in scale, especially large language models. Modern threats, such as adversarial attacks and leaks through open-source components, require the implementation of comprehensive protection measures.
Recommendations for ensuring security
Implement automation. Using tools like MLFlow and ART helps systematize processes and reduce the risk of human error;
Conduct regular audits. Checking data, models, and processes allows timely detection and elimination of vulnerabilities;
Train robust models. Using methods such as adversarial training and model ensembles increases resistance to attacks;
Control access. Segregation of rights and activity monitoring using IdM and PAM systems help prevent insider threats and data leaks necessary for work.
Pay attention to open-source components. Thoroughly check third-party solutions for compliance with security requirements. The analysis should be conducted based on vulnerability databases that include information about current threats targeting Russian companies. For example, the already mentioned Solar appScreener supports 36 programming languages, 10 executable file formats, and helps establish comprehensive software security control using the main code analysis tools − SAST, DAST, OSA – to reduce the risk of incidents caused by vulnerabilities in the code.










Write comment