- AI
- A
Session Calculators — The Key to Future Analytics Success
The eternal conflict: analysts demand freedom of action, while DBAs restrict database access, fearing a "killer" query that could crash the entire cluster. At Postgres Professional, we developed Tengri — a system where every user gets isolated computational resources. I explain how the architecture of individual calculators prevents resource competition and why, after this experience, returning to shared query queues is no longer desirable.
Hello everyone, my name is Nikolai Golov. I have spent my entire professional life building analytical platforms. You may have seen my articles about Vertica and Snowflake.
In recent years, I have been helping dozens of organizations build data platforms as a consultant. And almost always, our discussion with a new team would start with the same "Groundhog Day":
— business: "Analysts are working too slowly!";
— analysts: "We are not allowed to work directly with the database, we are forced to give tasks to data engineers and wait for weeks!";
— engineers: "How can we let them into the central DWH? Have you seen their queries? One forgotten ON in a join — and the database crashes, blocking both reports for the CEO and critical ETL processes."
I observed this scenario everywhere: in classic on-premise solutions (Greenplum, Vertica), in trendy Chinese solutions (StarRocks), and even in open-source Lakehouse installations (Spark). I was finally shocked by the case of a huge European food delivery company: they were using Databricks, had almost unlimited resources, but still suffered from mutual blocking and resource contention.
Why, in 2026, are we still unable to isolate the activity of one analyst from the rest of the company? Why should an individual mistake harm colleagues?
What is the root of the problem?
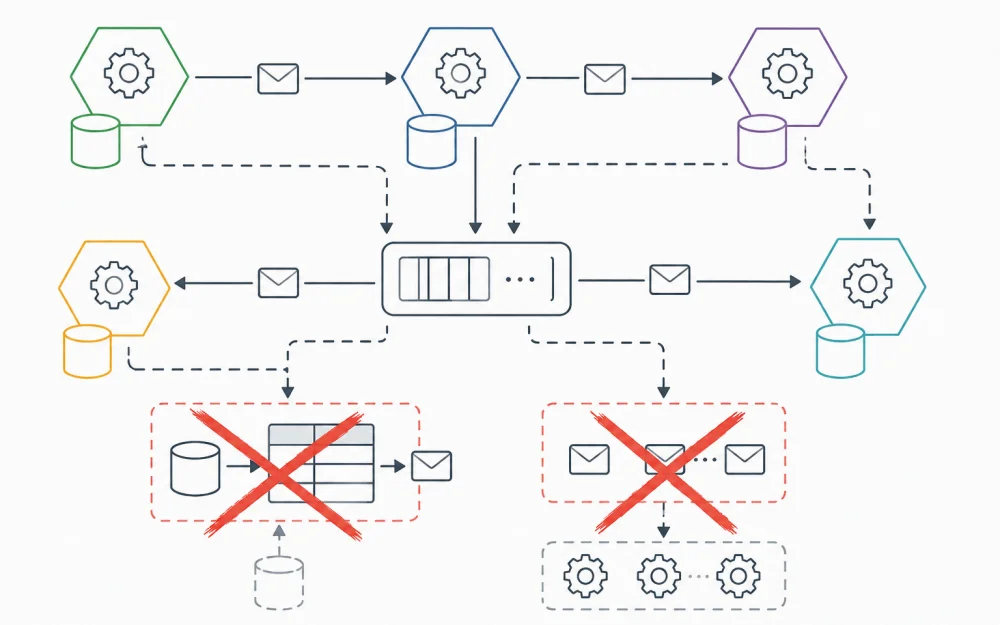
The issue is that most DBMS systems, for historical reasons, are designed to process queries via a "single route", which inevitably creates bottlenecks:
-
Greenplum (Shared-Nothing architecture). Any query goes through the coordinator node. Even if you have hundreds of segments, the coordinator becomes a single point of failure and a bottleneck for metadata and query planning. But worse is this: a heavy read query "eats up" resources (CPU/Interconnect) on all segments simultaneously, causing other queries to pile up in queues.
-
Vertica. There is no single coordinator here, but there is a "global catalog." Each query requires synchronization of nodes through this catalog. Once one analyst launches a "heavy" session, the locking mechanisms (GOS/Ros Pushdown) start to slow down the entire cluster's performance.
-
Spark and StarRocks. Despite their modernity, they often allow the "resource exhaustion" situation. One incorrect query occupies all available slots (executor cores) on nodes, and the system simply stops accepting new tasks.
Of course, all of these databases have "workarounds": resource groups, pools, quotas. But their proper configuration requires a DBA with a "god-level" qualification, which is often absent in regular companies. And most importantly — these tools only try to limit the damage but do not eliminate the root cause of resource contention.
Dream Database for Analytics
What should a database look like where analysts can truly have full freedom? Imagine: each analyst works in their own personal database. They see real-time data, but physically they do not share the "hardware" with their neighbor.
Fantasy? No, Snowflake was the first to prove that this is possible, by implementing the architecture of Multi-cluster Shared Data:

-
Storage (S3). Data is stored separately, it is cheap and infinite.
-
Metadata Layer. A unified KV-DB stores transactions and statistics, answering the question "where are the required partitions located?".
-
Compute (Virtual Warehouses). And here's the magic. These are independent compute nodes that start instantly, only pull the required data from S3 into local cache, and shut down after completing the task.

I spent 6 years with Snowflake and I can confirm: once you get used to the fact that your colleague can launch the heaviest ML process on a neighboring Warehouse, while your BI dashboard doesn’t even “hiccup,” going back to old architectures becomes physically painful.
Understanding that Snowflake’s path is the only way to give analysts true isolation, we at Postgres Professional decided to build our own system with a similar architecture, but taking into account all the “pains” and limitations that Snowflake users have accumulated over the years.
This is how Tengri (Tengri Data Platform) was born.
If you look at the diagram, architecturally we are very similar to Snowflake, but as always, the devil is in the details. We decided to remove the “proprietary walls” and build the system on an open stack.

What are the key differences from Snowflake?
Open data format (Apache Iceberg vs Proprietary)
Snowflake stores data in its own closed binary format. If you decide to leave them, be prepared for a long and expensive egress.
In Tengri, data is stored in S3 in the open Apache Iceberg format (internally standard Parquet). This means your data belongs to you. You can connect Spark, Trino, or any other tool to it directly through Tengri or bypassing the DBMS itself. No vendor lock-in.PostgreSQL emulation
Snowflake has its own SQL dialect. We chose the path of maximum compatibility. Our SQL Endpoint emulates Postgres behavior. For any BI tool or driver (ODBC/JDBC), Tengri looks like a regular Postgres. This allows the system to be seamlessly integrated into existing infrastructure.On-premise and any cloud
Snowflake is only available in public clouds (AWS/Azure/GCP). Tengri, on the other hand, can live anywhere: in your private cloud or on bare metal. For many large companies in 2026, this is a critical requirement.
Why Python? (And what do LLMs have to do with it?)
When we started designing the system, we faced a choice: take ready-made open-source components (Trino, Presto, Hive Metastore) and try to glue them together with “blue duct tape.” But that path leads to hell: each component has its own legacy, its own inconsistencies, and tons of extra code that is simply useless in our architecture.
We decided to take a different path — to implement all the “building blocks” ourselves in Python.
Sounds like madness for a DBMS? Actually, no. Modern Python is not just about scripts; it's a powerful ecosystem of libraries for data processing (Apache Arrow, Polars, DuckDB-engine, and others), where all the heavy math and memory handling are already written in C++ and Rust.
Choosing Python was a conscious decision for us to avoid the "legacy trap": instead of spending years adapting bulky open-source engines with tons of unnecessary code and architectural layers, we implemented only the functions we needed, relying on the performance of modern data processing libraries. In this synergy, our years of experience in data engineering and the capabilities of LLMs worked perfectly: neural networks took over the routine generation of code and typical structures, allowing us to fully focus on high-level architecture and seamless component integration. The process went so organically and quickly that it felt like the system itself was eager to be written, freeing us from fighting low-level "noise" and allowing us to immediately jump to implementing the concept of ideal session-based compute engines.
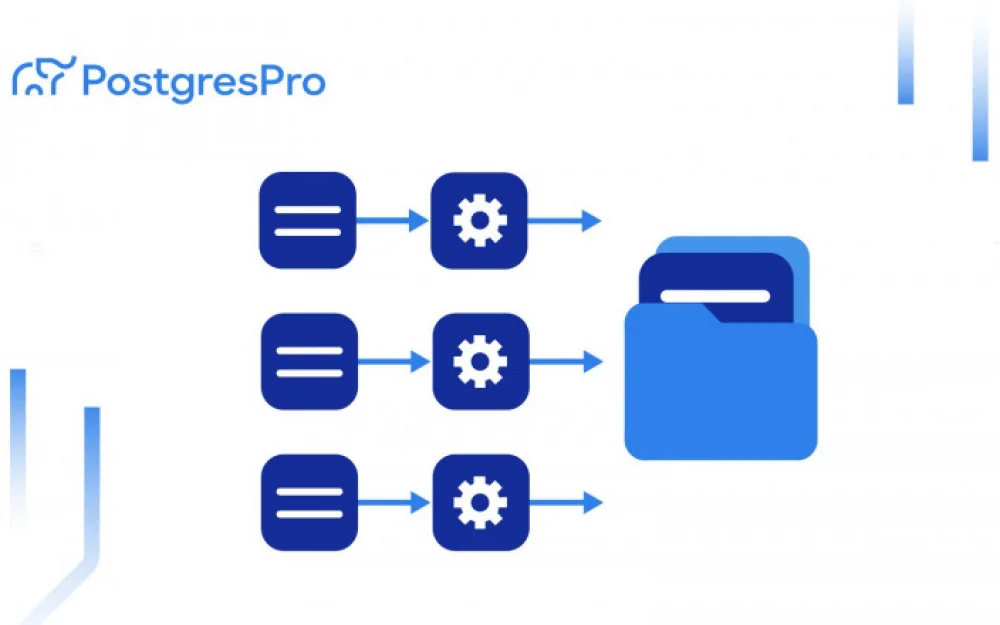
As a result, we got lightweight SQL compute engines (daemons) that start in fractions of a second, pull the required data from Iceberg, and return the result without interfering with neighbors.
The diagram above clearly illustrates what session-based compute engines provide in practice. We compared Tengri with Cloudberry 1.6.0 (a modern fork of Greenplum 7 based on Postgres 14) on the standard TPC-H benchmark (sf=100). To ensure a fair test, we allocated comparable resources to the systems: 100 vCPUs for Tengri versus 120 vCPUs for Cloudberry. We should immediately note that the performance data was obtained in a strictly controlled environment at Postgres Professional while modeling the expected analytical workloads and is for reference purposes only. Results obtained under different conditions may vary.
What the numbers show:
The difference between the systems is approximately 1.6 times (496 requests per hour for Tengri versus 304 for Cloudberry). This is the "base" difference in engine performance when they do not have to share resources with colleagues.
When users are added, Cloudberry starts to predictably "saturate." When moving from 10 to 20 parallel threads, its overall performance increases by only 24%. This is the "bottleneck" of the architecture: requests begin to fiercely compete for shared resources and locks.
Our system demonstrates almost linear growth up to 10 threads and maintains high efficiency at 20. Where Cloudberry processes 1800 requests per hour, Tengri handles 7311 — this is already a fourfold gap.
Each new analyst in Tengri receives their isolated compute, so the system efficiently utilizes the available hardware rather than wasting CPU cycles waiting in the coordinator’s queues. Of course, as the load continues to grow, we will also hit the physical resource limits, but this "saturation" point in our architecture can be pushed almost indefinitely simply by adding new nodes to the cluster.
PS. I will be happy to answer any questions that arise.
PPS. We are open for pilot projects, either in public clouds or on your hardware.











Write comment