
- AI
- A
Breakthroughs in image generation. What has changed with the advent of multimodal models?
I explain in detail with examples of creating infographics, editing interiors, prototyping websites, and advertising concepts, all done using simple text prompts.
Hello everyone!
My name is Alexander, I’m the COO at a data analytics SaaS platform. For the past year, I’ve been actively exploring the integration of AI solutions into cross-functional processes. I’m sharing resources that help:
Product managers — integrate AI without overloading their teams;
Developers — choose tools tailored to specific business tasks;
Data specialists — avoid mistakes in production deployment.
On my Telegram channel I share concise, structured article summaries.
Today’s translation — No elephants: Breakthroughs in image generation
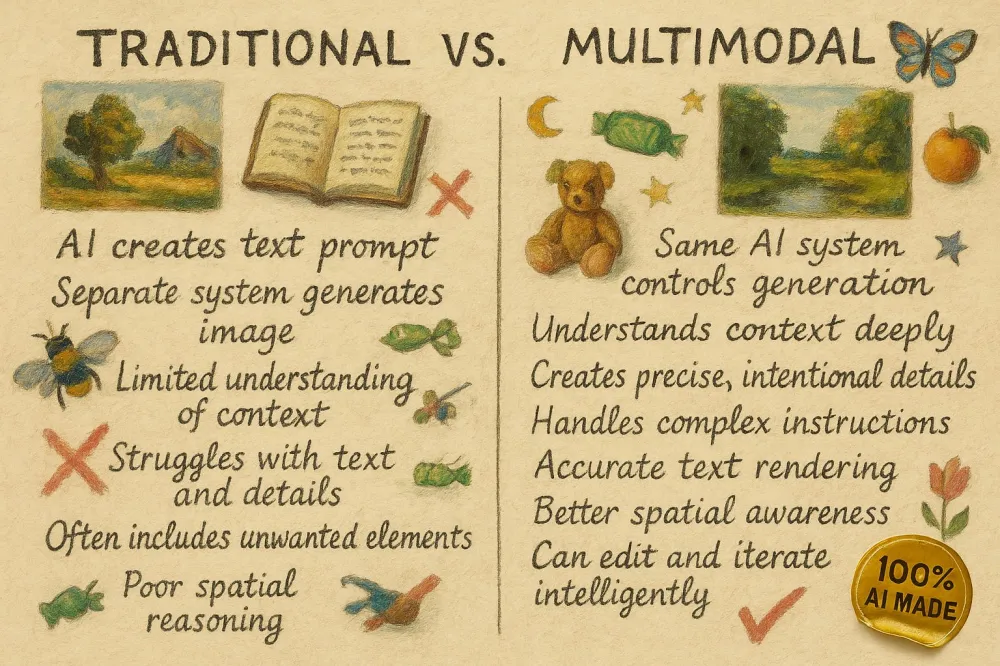
The article explores the breakthrough in image generation technology that came with the advent of multimodal models from Google and OpenAI. Unlike previous systems, where language models only composed prompts for separate image generators, new AIs create visual content directly, “assembling” it from parts much like words in a sentence.
Key insights:
multimodal models provide unprecedented control over the result via simple text prompts
you can iteratively edit images using natural language
the line between professional design and AI generation is rapidly blurring, changing many creative professions.
The article demonstrates concrete examples of creating infographics, editing interiors, prototyping websites, and developing ad concepts with simple text requests, unlocking new opportunities for designers, marketers, and content creators.
Over the past two weeks, first Google and then OpenAI have unveiled their multimodal image generation capabilities. This is a very significant event. Previously, when a large AI language model generated an image, the model didn’t do the work itself. Instead, the AI sent a text prompt to a separate image generation tool and showed you the result. The AI would create the prompt, but another, less intelligent system would create the image. For example, if you asked for "show me a room without any elephants, but be sure to add annotations to the image to show why there are no elephants here," the less intelligent image generation system would see the word "elephant" several times and add them to the picture. As a result, AI-generated images were pretty mediocre — with distorted text and random elements; sometimes funny, but rarely useful.
Multimodal image generation, on the other hand, allows AI to directly control the creation of images. While there are many variations (and companies keep some of their methods secret), in multimodal image generation, images are created in the same way as LLMs create text — one token at a time. Instead of adding individual words to form a sentence, the AI creates an image from individual fragments, one after the other, which are assembled into a whole picture. This allows the AI to create much more impressive and accurate images. Not only do you get a guarantee of no elephants, but the final results of this image creation process reflect the "thinking" intelligence of the LLM, as well as clear text and precise control.

While the implications of these new image models are vast (and I'll touch on some issues later), let's first explore what these systems are really capable of, with a few examples.
Prompts, but for images
In my book and in many publications, I talk about how a helpful way to interact with AI is to treat it like a person, even though it’s not. Clear instructions, feedback during iteration, and the appropriate context for decision-making help people, and they also help AI. This used to be possible only with text, but now it is also possible with images.
For example, I asked GPT-4o to create an infographic on how to make a good board game. With previous image generators, this would have resulted in a meaningless output, as there was no intelligence to control the image generation, so the words and images would be distorted. Now, I get a good first version right away. However, I didn't provide any context about what I was looking for or any additional content, so the AI made all the creative decisions by itself. What if I want to change it? Let’s try.
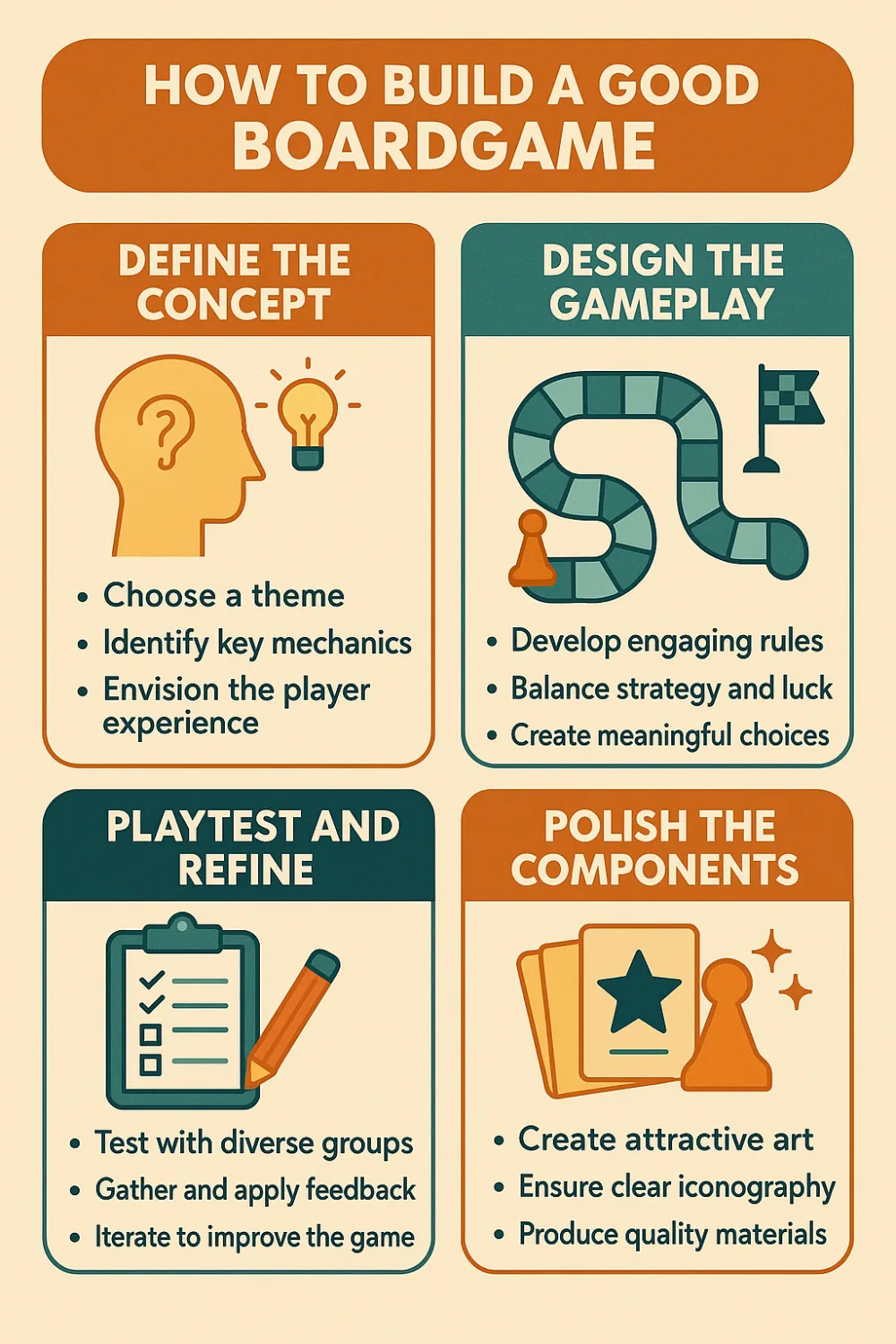
First, I asked to "make the graphics hyper-realistic", and you can see how he took concepts from the original version and updated their look. I had more changes I wanted to make: "I want the colors to be less earthy and more like textured metal, keep everything else as it is, also make sure the small bullet-pointed text is lighter to make it easier to read". I liked the new look, but I noticed a mistake, the word "Define" turned into "Definc" – a sign that these systems, no matter how good they are, are still far from perfect. I made a request "You wrote Define as Definc, please fix it" and got the desired result.

But the most exciting thing about these models is that they can create almost any image: "put this infographic in the hands of an otter standing in front of a volcano, it should look like a photo, and as if the otter is holding it, engraved on a metal plaque".

Why stop there? "It's night now, the plaque is lit by a flashlight shining right into the center of the plaque (no need to show the flashlight)" — the results of this are even more impressive than they may seem, because the model adjusted the lighting without any basic lighting model. "Create an action figure of the otter in a package, make a board game one of the side accessories. Call it 'Otter Game Designer' and give it a couple of other accessories." "Make the otter in an airplane using a laptop, it buys a copy of the Otter Game Designer from a website called OtterExpress." Impressive, but not quite right: "Fix the keyboard so it's realistic, and remove the otter figure it's holding".

As you can see, these systems are not flawless... but also remember that the images below are the results of the request "otter in an airplane using Wi-Fi" from two and a half years ago. Cutting-edge technology is rapidly advancing.

What could this be useful for?
For the past couple of years, we've been trying to figure out what text-based AI models are good for, and new use cases are being developed all the time. The same will happen with image-based models. Image generation will likely be highly disruptive in areas we don’t yet understand. This is especially true because you can upload images that LLM can now directly see and manipulate. Here are a few examples, all done using GPT-4o (although you can also upload and create images in Gemini Flash by Google):
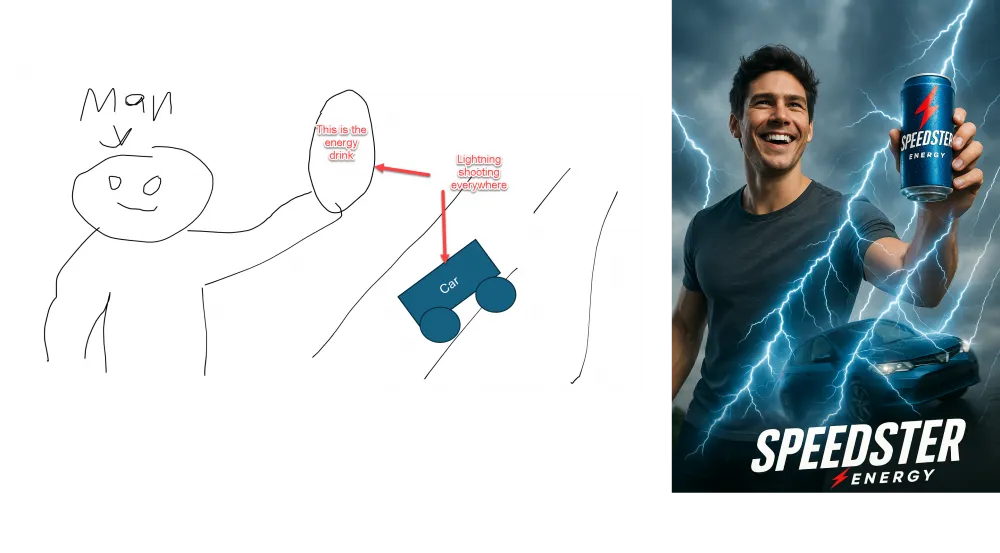
I can take a hand-drawn image and ask AI "turn this into an ad for the Speedster energy drink, make sure the packaging and logo are gorgeous, it should look like a photo". (This took two prompts; the first time it spelled Speedster wrong on the label.) The results aren’t as good as what a professional designer might create, but it’s still an impressive first prototype.
I can give GPT-4o two photos and ask "Can you replace the coffee table in the photo with the blue couch with the one from the photo with the white couch?" (Notice how the new glass tabletop reveals parts of the image that weren’t in the original. On the other hand, the replaced table is not exactly the same.) Then I asked: "Can you make the rug less faded?" Again, there are some details that aren’t perfect, but this kind of image editing in plain English just wasn’t possible before.

Or I can instantly create a website mockup, ad concept, and presentation for my excellent startup idea where a drone delivers guacamole on demand (I’m sure it’ll be a hit). You can see this isn’t a replacement for flashes of human designer insight, but it’s still an extremely useful first prototype.

Beyond that, there are plenty of other uses that I and others are discovering, including: visual recipes, homepages, video game textures, illustrated poems, nonsense monologues, photo improvements, and visual adventure games, just to name a few.
Challenges
--- Turn your hand-drawn sketches into polished ads and stunning photo edits instantly with AI—start creating your prototypes today!If you’ve been following the online discussion around these new image generators, you’ve probably noticed that I haven’t demonstrated their most viral use—style transfer, where people ask AI to transform photographs into images resembling those created for “The Simpsons” or by Studio Ghibli. Such applications highlight all the complexities of using AI for art: is it right to have AI reproduce another artist’s hard-earned style? Who owns the resulting artwork? Who profits from it? Which artists are in the AI’s training data, and what’s the legal and ethical status of using copyrighted works for training? These were important questions even before multimodal AI appeared, but now finding answers is becoming ever more urgent. Plus, of course, there are many other potential risks associated with multimodal AI. Deepfakes have been trivial to create for at least a year, but multimodal AI makes it even easier, including the ability to create all sorts of other visual illusions, such as fake checks. And we still don’t understand what kinds of biases or other issues multimodal AIs might introduce into image generation.
However, it’s clear that what happened with text will happen with images, and eventually with video and 3D environments too. These multimodal systems are reshaping the landscape of visual creativity, offering powerful new possibilities while simultaneously raising legitimate questions about creative ownership and authenticity. The line between human and AI-generated creativity will keep blurring, making us reconsider what constitutes originality in a world where anyone can generate complex visuals with a handful of prompts. Some creative professions will adapt; others might remain unchanged, and some may be transformed entirely. As with any significant technological shift, we’ll need well-considered foundations to navigate the complex terrain ahead. The question isn’t whether these tools will change visual media, but whether we’ll be thoughtful enough to shape that change intentionally.










Write comment