
- Hardware
- A
Why server architecture has become what it is and what will change in the near future
Hello! This is Dmitrii Shichenko, head of the embedded systems development department at Selectel. Throughout the history of both servers and desktop computers, the motherboard has always remained the central element. It determines not only the compatibility of components but also the overall performance, scalability, and energy efficiency of the entire platform.
Its architecture is not just a physical basis for placing the processor, memory, and connecting peripherals. It is a complex logical structure that reflects the evolution of computing power, technological limitations, and market demands.
In this article, we will recall how the architecture transformed, how the functions of the north and south bridges were divided, and how their roles changed. We will analyze further integration with modern processor solutions. We will look into the future and anticipate scenarios for the development of server technologies.
Function division: north and south bridges in classic architecture
In the early stages of the development of personal computers and servers, the level of integration of semiconductor components was limited by manufacturing technological capabilities. The processors of that time could not accommodate all the necessary controllers and interfaces due to technological constraints.
On the motherboard, it was necessary to provide for additional chips — chipsets. They ensured interaction between the central processing unit and other components. This is when the classic dual-bridge architecture was formed, which defined the development of x86 platforms for decades.
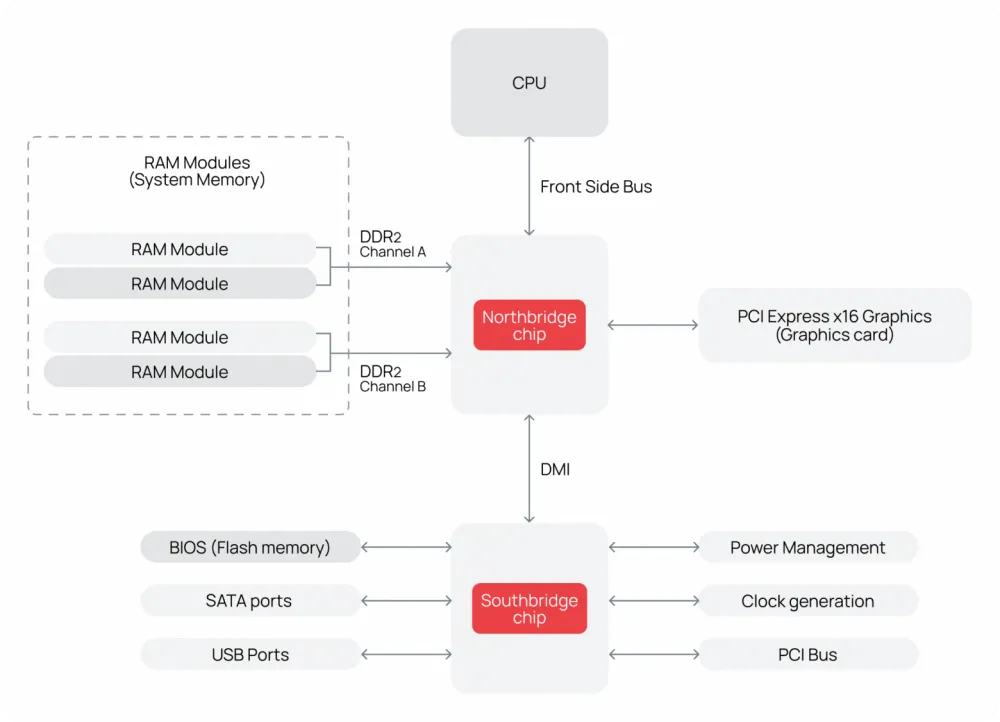
The North Bridge occupied a central position on the board to be as physically close to the processor as possible. Only in this way can data exchange delays be minimized, as the bus length is a critical parameter: the shorter it is, the less loss due to signal attenuation and parasitic coupling, which means higher overall performance. The North Bridge manages the highest-speed subsystems:
memory controller, which is responsible for data exchange between the CPU and DRAM;
graphics accelerator interface, supporting the operation of discrete graphics cards via AGP or PCIe buses, as well as managing integrated graphics cores;
high-speed PCIe lanes — an interface for connecting fast devices such as SSD drives or network adapters (in later implementations, the North Bridge was also responsible for distributing PCIe lanes).
For working with high-frequency signals, the North Bridge was often referred to, especially at Intel, as the "graphics and memory controller" (Graphics and Memory Controller Hub, GMCH).
The South Bridge, on the other hand, was located on the periphery of the board and was responsible for managing low-speed, but numerous input-output interfaces:
SATA controllers for connecting HDDs and SSDs;
USB ports of various generations;
Audio and network controllers;
Power management, timers, RTC, and other auxiliary functions.
This division was not accidental; it allowed for:
optimizing the routing of the printed circuit board,
maintaining signal integrity requirements,
minimizing its losses and attenuation.
High-speed pathways from the processor to memory and GPU required short differential pairs. Low-speed interfaces, on the other hand, allowed for longer ones.
A differential pair is a method of transmitting high-speed signals over two closely spaced conductors. The signals are of equal magnitude but opposite polarity—direct and inverted. The voltage difference between them allows the receiver to filter out noise, thus increasing the reliability and speed of transmission.
The Path to Integration — The Disappearance of the North Bridge
With the development of semiconductor technologies—in particular, with the transition to 45 nm, 32 nm processes, and beyond—it became possible to place more and more functional blocks directly within the processor chip. The architecture of motherboards began to change irreversibly.
The first major step was the integration of the memory controller into the processor core. Leading the way, AMD implemented this concept in the K8 (Athlon 64) architecture back in 2003. Following its example, Intel released its Nehalem in 2008. Directly connecting the CPU to RAM significantly reduced access delays, increased bandwidth, and simplified the board topology.
The next stage was the integration of the iGPU graphics core directly into the CPU chip. In server architectures, priority is given to computational density and memory bandwidth. Discrete graphics had long been considered redundant and only required for console output. The integration of the iGPU allowed for the elimination of discrete graphics cards in basic configurations, which reduced both cost and power consumption.
It is especially important that control of the PCIe lines for connecting graphics cards, NVMe drives, and high-speed network controllers has transitioned into the processor. The other, less prioritized lines are still routed through a single chipset—the PCH (Platform Controller Hub), which has become the successor to the southbridge and implements input-output interfaces—SATA, USB, BIOS, and others. PCIe and PCH are connected to each other via the DMI bus (Direct Media Interface) at Intel and IFL (Infinity Fabric Link) at AMD.
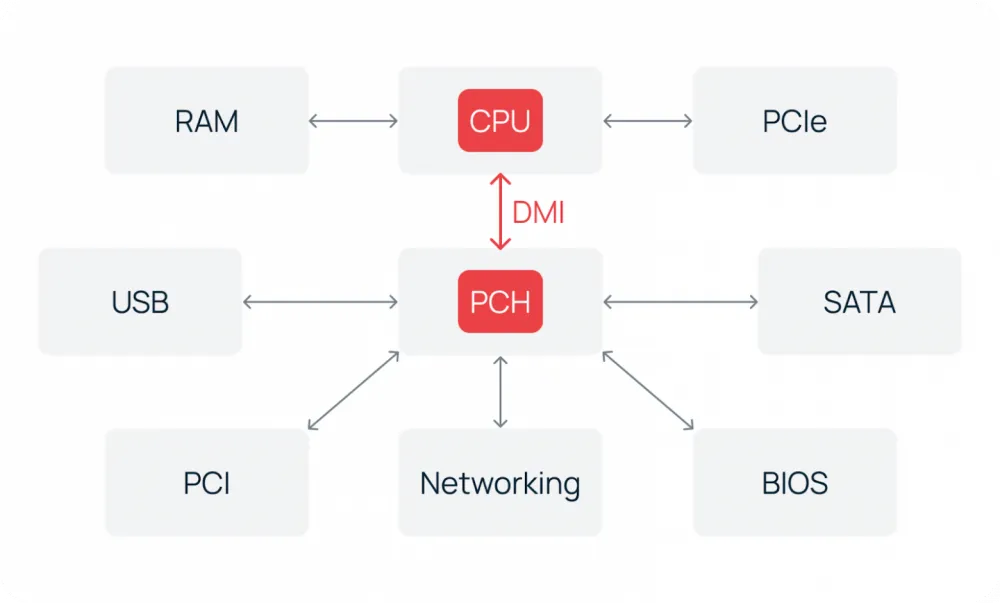
As a result of all these changes, the northbridge has completely disappeared. On Intel platforms, starting with the Sandy Bridge generation in 2011, it has been fully integrated into the processor. A similar transition occurred at AMD with the ZEN architecture in 2017. In server segments, two-chip configurations remained longer due to the requirements for the number of PCIe lanes and support for multiprocessor configurations.
Nevertheless, the logical division of functions has been preserved. Even in modern processors, one can distinguish the "north" part (cores, cache, memory controllers, PCIe) and the "south" part (input-output interfaces managed by the chipset via high-speed DMI or IFL).
The evolution has radically changed server motherboards:
topology has simplified—fewer chips, fewer PCB layers, reduced costs, increased reliability;
latency and power consumption have decreased—direct connection of memory and PCIe devices to the CPU eliminates intermediate links;
management has centralized—the chipset has turned into the "south tekkix," providing peripheral connections, but no longer participating in critical data paths.
CPU-Centric System
At the beginning of 2026, the latest generations of server processors were released—Intel® Xeon® 6 (Granite Rapids and Sierra Forest) and AMD EPYC™ 9005 (Turin). With their appearance, there has been a definitive transition to a paradigm in which the PCH and its analogs have lost the status of essential components of the motherboard. We are witnessing the logical conclusion of a years-long integration path that began with the disappearance of the northbridge.
Intel and AMD have different approaches in detail, but they lead to a unified result. All critical logic for managing data flows is now concentrated directly in the processor module.
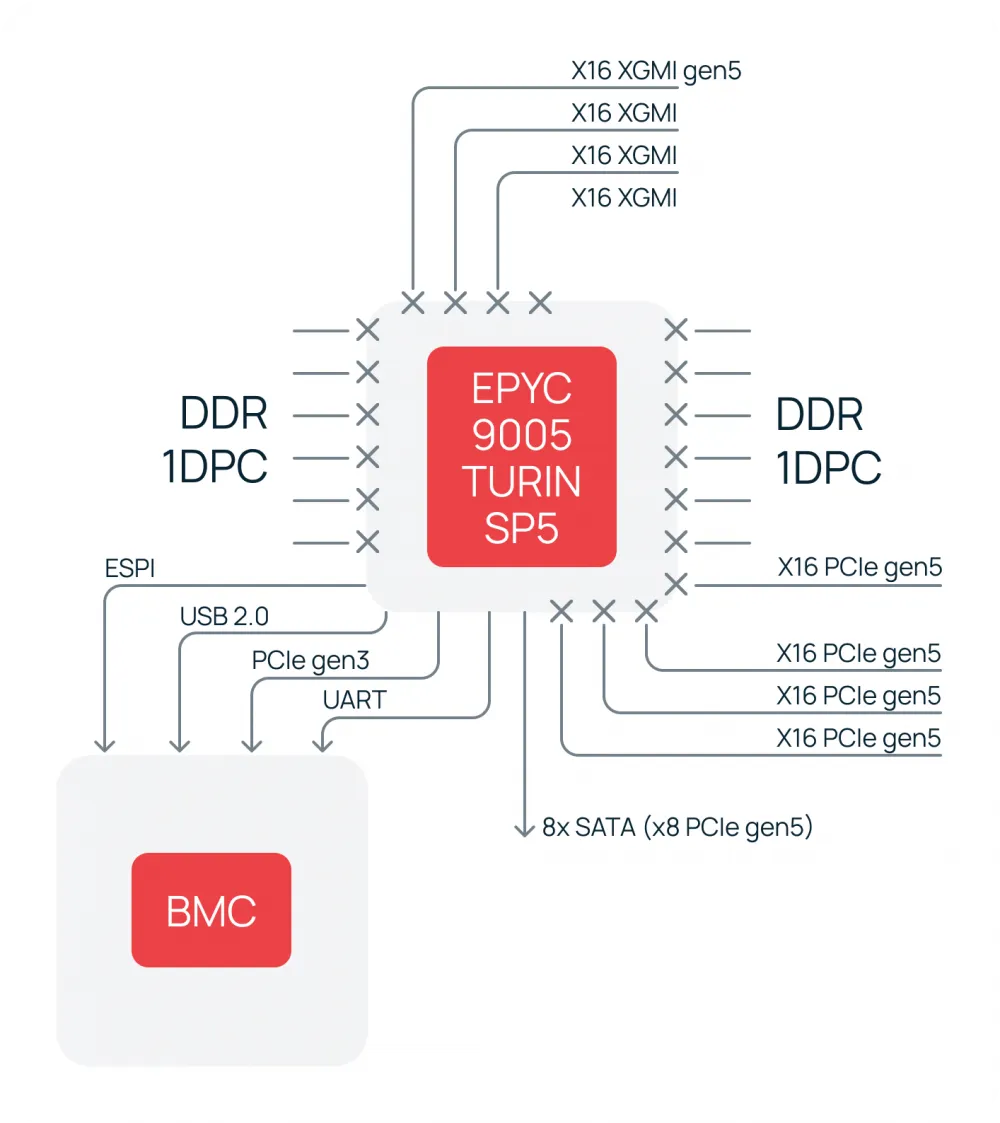
AMD prepared the groundwork for such an architecture in advance. Starting with the Zen 2 generation (EPYC™ Rome), they moved away from the classic external chipset. Instead, they integrated all the functions of the southbridge into a specialized I/O Die chip within the multi-chip module (MCM).
In the flagship EPYC™ 9005 (Turin), this concept reached its highest development. The central I/O Die provides up to 12 channels of DDR5‑6400 memory and 128 PCIe 5.0 lanes with the potential for up to 160 in two-processor systems. Additionally, built-in support for interfaces such as SATA and CXL 2.0 is maintained.
As a result, for most server configurations, the external chipset becomes redundant. It is now only needed to increase the number of ports, but not for basic functionality.
This principle guided us in developing our next-generation server platforms with the EPYC™ 9005 processor. Below is the functional diagram of the Selectel motherboard. All critical resources—memory, expansion, network interfaces—connect directly to the processor through its built-in controllers.
Intel acted just as decisively. In previous generations, including the 4th Gen Xeon® Scalable (Emerald Rapids), the Emmitsburg PCH chipset (Intel® C740 Series Chipsets) was still used. However, with the 5th Gen Intel® Xeon® Scalable and newer Xeon® 6, progress becomes more radical.
Management of all key high-speed subsystems, such as memory and PCIe, is integrated directly into the chip. Secondary low-speed interfaces—USB, SATA, or Ethernet—can have discrete controllers on the motherboard. However, their physical transport layer is nothing but PCIe! This means that even peripheral devices are logically connected to the CPU, rather than to a separate input-output hub.
This concept can also be seen in our first development — the Selectel server based on Intel® Xeon® 6. In particular, the SAS and SATA interfaces are implemented by separate controllers and connected to the Gen 5 processor via a PCIe bus. Additionally, discrete controllers for USB and Ethernet are provided on the motherboard without involving the northbridge.
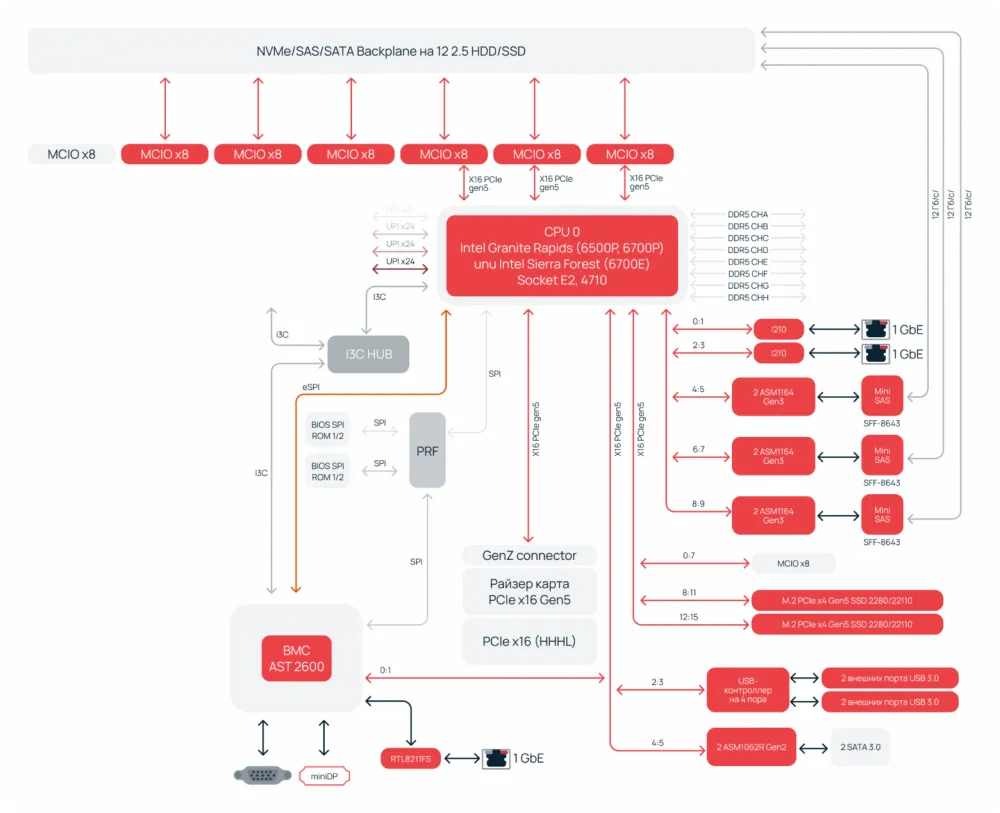
As a result, the once complex hierarchical structure based on the interaction of the CPU, northbridge, and southbridge has been reduced to a minimalist topology. There is a processor, its direct connections to the RAM and PCIe devices, as well as a BMC management controller. The motherboard has transformed from an active participant in data processing into a high-speed, but passive, switching medium. Its role now is to transmit signals and power the powerful processors, ranging from 300 to 500 watts.
This fundamental shift in architecture not only radically simplified design and reduced manufacturing costs but also opened the way for the creation of even faster and more energy-efficient servers with a dense arrangement of components. Such requirements are critically important for modern data centers focused on AI, cloud computing, and high-performance tasks.
The evolution that began with the division of functions between bridges has culminated in their complete dissolution in the very heart of the computing system.
The future lies in disaggregation — modular servers and scalable architecture
The evolution of the motherboard at the beginning of the 21st century is currently moving towards the consolidation of functions within the processor. However, the next stage will involve their purposeful extension beyond it, but at a different technological level.
The concept of the future server is not to be tied to either a physical board or even a unified chassis. Instead, a dynamic, flexible “computing wall” is being formed, where all resources — processors, memory, storage, accelerators — are combined based on the principle of “plug-and-compute” using high-speed interconnects. This creates the possibility of pooling computing resources that will operate as a cohesive array with parallel data processing.
This paradigm is called Resource Disaggregation. It implies a complete rethinking of the role of the motherboard. It ceases to be a static foundation for a fixed set of components and transforms into a universal switching tekkix capable of adapting to changing workloads.
Block Assembly of Supercomputers
The server of the future will be assembled from "bricks," like a wall. The basic chassis will provide power, cooling, and backbone switching. Other resources will connect as separate blocks:
computational — CPU, GPU, FPGA;
memory — volatile and non-volatile;
storage — NVMe SSD, SAS/SATA SSD, HDD;
network infrastructure — SmartNIC, DPU.
All components will interact through a single high-speed interface.
Which one? It is still unclear.
One of the main contenders is Compute Express Link (CXL), a protocol that provides inter-component connection at the cache and memory transaction level. Its key feature is high bandwidth and a shared address space (data coherence). In other words, CXL allows both the processor and the graphics accelerator to interact with memory beyond their own server rack with minimal latency.
Our Selectel server uses the latest Xeon® 6 processors and already supports CXL 1.2 and 2.0. We are actively testing the technology. If you want to join the experiment, please apply on the website.
To date, the development of interconnect resembles a technological rally. Several protocols have emerged on the scene simultaneously—each with its own philosophy and application area. All of them—CXL, UCIe, CCIX, Infinity Fabric—respond to the same fundamental challenge of modern computing. However, the paths of their implementation differ fundamentally. The question is: "How to overcome the boundaries of a monolithic chip and turn tightly coupled components into dynamically managed resource pools?"
Some protocols, such as UCIe, operate at the micro level—inside the packaging, connecting chiplets on a common substrate. They essentially dissolve the boundaries of the processor itself, transforming it from a monolith into a conglomerate of specialized crystals bonded by a coherent bus.
Others, like CXL or CCIX, work at the macro level. Their domain is the server board, rack, and potentially an entire data center. These enable the processor to "look" beyond its enclosure and address memory or an accelerator physically located in a neighboring block while maintaining coherence and low latency.
AMD's Infinity Fabric occupies an intermediate niche, providing scalability from multi-chip modules to multiprocessor servers.
However, the transition to disaggregated architecture faces several fundamental limitations. Their roots lie in the physical and structural features of existing interconnects. The foundation of the CXL ecosystem is the PCIe bus, which was not originally designed for coherent access to remote resources. Its sequential nature imposes three critical limitations.
1. Transaction Latency manifests when working with remote compute pools. Launching a task on a processor or accelerator outside the local node requires not just data exchange but also synchronization: cache states, handling interrupts, and returning results. The cumulative delay easily exceeds 5–10 µs, making this approach unsuitable for short-lived, low-latency transactions.
The effective use of remote computational resources becomes possible only with batch processing or long-running tasks. In such cases, the communication overhead is amortized by the amount of useful work.
2. The transmission range decreases due to the physical limitations of the medium. High-speed PCIe Gen5/6 serializers (32 GT/s) are subject to critical attenuation on passive copper traces — over 25 dB/m at frequencies above 16 GHz. In typical implementations without additional amplification, the distance between nodes is reduced to 30−50 cm. Overcoming this barrier requires the introduction of active copper cables (ACC) or optical transceivers (AOC). However, such solutions increase power consumption by 3−5 W per link and add an additional 20−50 ns latency at the retransmission stage.
3. Coherence scalability is another critical barrier. Cache coherence maintenance algorithms, such as MESI, become exponentially more complex as the memory pool expands. In "star" or "fat-tree" topologies, CXL switches become bottlenecks — their buffers and translation lookaside buffer (TLB) limit the number of concurrent transactions. Additional load is created by sending cache invalidation signals — this background traffic consumes useful channel bandwidth.
So. Current limitations dictate a strategy of hierarchical disaggregation of interconnects. At the micro level, protocols like UCIe minimize latency within the package. The delay in establishing a connection between chiplets is no more than 10 ns. At the same time, they form a "coherent island" of high-performance resources. At the macro level, CXL and its successors, including the concept of CXL over optical fabric, provide effective rack aggregation without claiming ultra-low latency.
This approach confirms the absence of a universal protocol for all system elements — from the die to the data center. The future lies in multi-layer architecture: each level of interconnect is optimized for its scale, and resource management is transferred to the software layer, which hides physical compromises behind the abstraction of a unified computing environment.
The processor as a replacement module
The key element of the concept is the replaceable computing module. Imagine a motherboard with a unified connector or interposer compatible with different generations of CPUs and even manufacturers. This cross-platform capability is achievable through zone standardization of pins: designated areas of the socket will be responsible for specific functions — I/O (PCIe), DRAM, Power Management, and others.
We immediately gain several advantages:
extended lifecycle — upgrading the computing core will not require replacing the entire board;
configuration flexibility — the ability to choose a CPU for specific workloads: from energy-efficient models for background processes to multi-core solutions for HPC;
operational optimization — repair and maintenance in data centers are simplified due to the quick replacement of the computing unit.
Such modules will combine not only the processor but also built-in memory controllers, PCIe, and CXL, turning into fully independent computing units.
Selectel Server is a product that must not only meet the demands of the modern market but also be flexible regarding customer needs. Therefore, we recently announced the expansion of our server solutions lineup and introduced a board based on AMD EPYC™ 9005 Turin.
Memory and Storage as a Service
The CXL.mem and CXL.io protocols in the CXL 2.0+ standard are changing the architecture. Memory and storage are no longer tied to a specific CPU. Instead of a rigid coupling of components, flexible resource pools are created.
Memory Pooling — multiple servers share a common DRAM array. Capacity is dynamically allocated among virtual machines or containers, eliminating idle time and memory fragmentation.
Storage Class Memory over Fabric — ultra-fast non-volatile storage connects directly to the memory bus. The boundary between RAM and storage is blurred. This opens the way to new data models — for example, In-memory DB with instant recovery after failures.
These protocols guarantee three important features.
Cache coherence — data in remote memory is automatically synchronized with processor caches. There is no need to manage consistency programmatically.
Acceptable latency — the delays when accessing the pool are higher than those to local DRAM, but are limited to a few hundred nanoseconds. For most application layer tasks, such a difference remains unnoticed. Performance is usually bottlenecked by internal logic, data serialization, or the network stack. Transitioning to memory pools does not cause significant speed degradation, while radically increasing system flexibility.
Scalability — this architecture allows for virtually limitless memory expansion. For the pool, modules can be chosen with the optimal balance of price and density — from RDIMM to specialized CXL solutions based on LPDDR5X or energy-efficient DDR5. Such flexibility is especially relevant in conditions of an unstable component market and growing pressure on TCO (Total Cost of Ownership) — instead of expensive high-frequency memory in each node, a single efficient pool is deployed, shared among several computing blocks.
Transparency for OS and applications — modern hypervisors and operating system kernels, such as Linux with CXL 3.0, see the pool as a regular NUMA node or an extension of local memory. No changes to application code are required — meaning that the technology can be integrated into existing infrastructure right now.
This architecture transforms a server rack into a scalable supercomputer with dynamic resource allocation — a kind of "iron cloud." The data center begins to function as a single computing organism.
Flexible VM expansion can request 1 TB of RAM, even if the local node is limited to 512 GB — the missing volume will be allocated from the shared pool in the neighboring rack.
In-memory analytics and real-time systems process huge datasets entirely in memory — thus avoiding performance degradation due to disk swapping.
Neural network training requires colossal amounts of memory to store weights and activations — the system dynamically allocates resources for these tasks, borrowing them from less loaded nodes.
The evolution of server motherboard architecture is not just a chronology of changes in chip layout on a limited area. It reflects not only progress in electronics but also a fundamental shift in the nature of computing itself. There is a transition from tightly coupled monolithic systems to flexible, software-defined, and resource-efficient infrastructures.
The motherboard as a switching point
The transformation of architecture is not an end, but a transition to a new stage. With the development of CXL and the concept of resource disaggregation, the classic motherboard is disappearing. The server is no longer limited by the confines of a single chassis. Processors, memory, and storage are becoming independent yet logically connected resources that form a dynamic computing environment.
Memory pooling, processors in hot-swap module format, and block assembly of "super servers" all affirm the rejection of hardware rigidity in favor of software flexibility. We also build upon these principles when developing our software-hardware products.
On Habr, there is a separate article dedicated to the philosophy of the Selectel server.
We do not just observe the evolution of the industry; we design our own servers based on this philosophy. At its core are three principles: modularity, universality, and a full development cycle. This allows us to create platforms where each component—from the chassis and backplane to the cooling system—is optimized for specific tasks. On one hand, dependence on rigid frameworks of ready-made vendor solutions disappears, while on the other, the ability to flexibly adapt the hardware to changing disaggregation standards emerges.



![From Virtual Hands to AI for Survivalists: Curious Open Agent OSes [and One Hardware Project]](https://cdn.tekkix.com/imgs/2026/05/habrcom/big/ce0b1057616faed51cd8b9f3b2b9.webp)


Write comment