- AI
- A
Claude Opus 4.6 vs GPT-5.3 Codex: how to choose the model for your tasks
On February 5, 2026, two major coding tools were released almost simultaneously: Claude Opus 4.6 and GPT-5.3 Codex. The internet immediately filled with comparisons of which is better, but in practice, this comparison is often off the mark.
At the same time as the release of Claude Opus 4.6 and GPT-5.3 Codex, it became clear that there is definitely no one best model for all occasions. They tackle different tasks and view the role of AI in development differently: Opus is closer to an architect and orchestrator of agents, while Codex resembles an executive tech lead who can tirelessly work on a problem for hours until success.
In this article, we analyze what exactly Opus 4.6 and GPT-5.3 Codex have brought to the table, how they perform in benchmarks and real work, and how to reasonably combine them in a team's stack.
Two models - two approaches
Claude Opus 4.6 is the flagship model from Anthropic, focusing on long context (up to 1M tokens in beta), complex reasoning, and managing agents/sub-agents. It effectively retains large repositories, knowledge bases, and multi-day sessions in memory.
GPT-5.3 Codex is a specialized version of GPT-5 from OpenAI, tailored for “agentic coding”: working in Codex applications, CLI and IDE, running tests, reading logs, clicking through UI, and automating computer tasks.
In other words, Opus 4.6 is more like a team leader of agents: it plans, reads extensively, and keeps the project context. Meanwhile, GPT-5.3 Codex is, in a sense, a stubborn, reliable executor: it does the work quickly, thoroughly, and dependably under test conditions.
Let’s systematically explore what’s new in Claude Opus 4.6 and GPT-5.3 Codex, and then understand which tool is better suited for what.
What’s new in Claude Opus 4.6
1. 1M tokens of context and long sessions
The main change is the context window up to 1,000,000 tokens. The basic limit remains at 200k, but for requests that exceed this limit, long context is activated with an increased rate.
What does this mean in practice:
You can load entire monorepos, large libraries, and documentation.
Conduct one long strategic/research session without constant truncation of history.
Process complex legal/finance cases with a stack of documents: contracts, policies, correspondence.
How much will this cost:
Standard: $5 / $25 for 1M input/output tokens (like Opus 4.5).
For requests of 200k+ tokens - premium rate $10 / $37.5 for 1M tokens.
2. Agent Teams in Claude Code
Instead of one long chain of actions, you can now run multiple sub-agents working in parallel within Claude Code:
each agent is responsible for its part of the task (for example, front-end, back-end, tests)
agents coordinate actions with each other
the developer can switch to any sub-agent and intervene manually.
This is particularly useful when the task involves a lot of reading (large repository, RFCs, documentation) and when the work can be naturally divided, for example: Agent A reviews architecture, Agent B handles fixes and tests, Agent C works on documentation.
3. Integration with PowerPoint and Enhanced Excel
Opus 4.6 is now focused not only on coding but also on office tasks.
If previously you could ask Claude to create a presentation, but the editable file needed to be transferred to PowerPoint. Now Claude works in PowerPoint as a sidebar. The integration reads your existing layouts, fonts, and slide templates. It generates slides that match your brand without the need to create them from scratch. This feature is available in Max / Team / Enterprise plans.
Updated Excel mode: the model first builds an action plan for a complex task, plus, it can now handle unstructured imports. You can now upload disparate CSVs or CRM exports and bring them into proper tables for further analysis - it supports multi-step edits in one pass (filtering, formulas, pivot tables).
This creates a good synergy: we upload raw data - Excel processes and structures it, and then, based on this, visually presents it in PowerPoint on slides.
By the way, the integration with PowerPoint reminded me of how it's implemented in Kimi Slides (I made a video review on it).
4. Adaptive Thinking and the team /effort
Previously, the extended thinking mode was either on or off. Now, Claude can decide when deeper reasoning will be useful - Opus 4.6 has introduced a adaptive thinking mode:
The model decides for itself whether to engage in prolonged reasoning for specific queries.
There are 4 levels of effort (complexity): low /medium /high (default) /max
The level can be set directly in the chat or via API.
Example command in the chat interface:
/effort highFor simple tasks (unit fixes, small scripts), it’s better to set medium to avoid wasting extra tokens. For complex architectural/research tasks - max, the model will think longer and return to intermediate hypotheses.
5. Context Compaction
To avoid hitting the ceiling during prolonged sessions, Opus 4.6 has received automatic context compaction:
Old parts of the dialogue/documents are collapsed into compact summaries.
These summaries are substituted for raw data when the context is close to the limit.
The idea is similar to RAG pipelines but built into the model itself. For developers, this is good - less manual
make a summary and then work with it.
6. Up to 128k Output Tokens
Opus 4.6 can produce up to 128,000 tokens of response in one go. This is great for large documentation files (docs, manuals, tutorials) without splitting. Also suitable for long code diffs and auto-generating entire modules, as well as for lengthy research/analysis reports.
7. Coding and Benchmarks
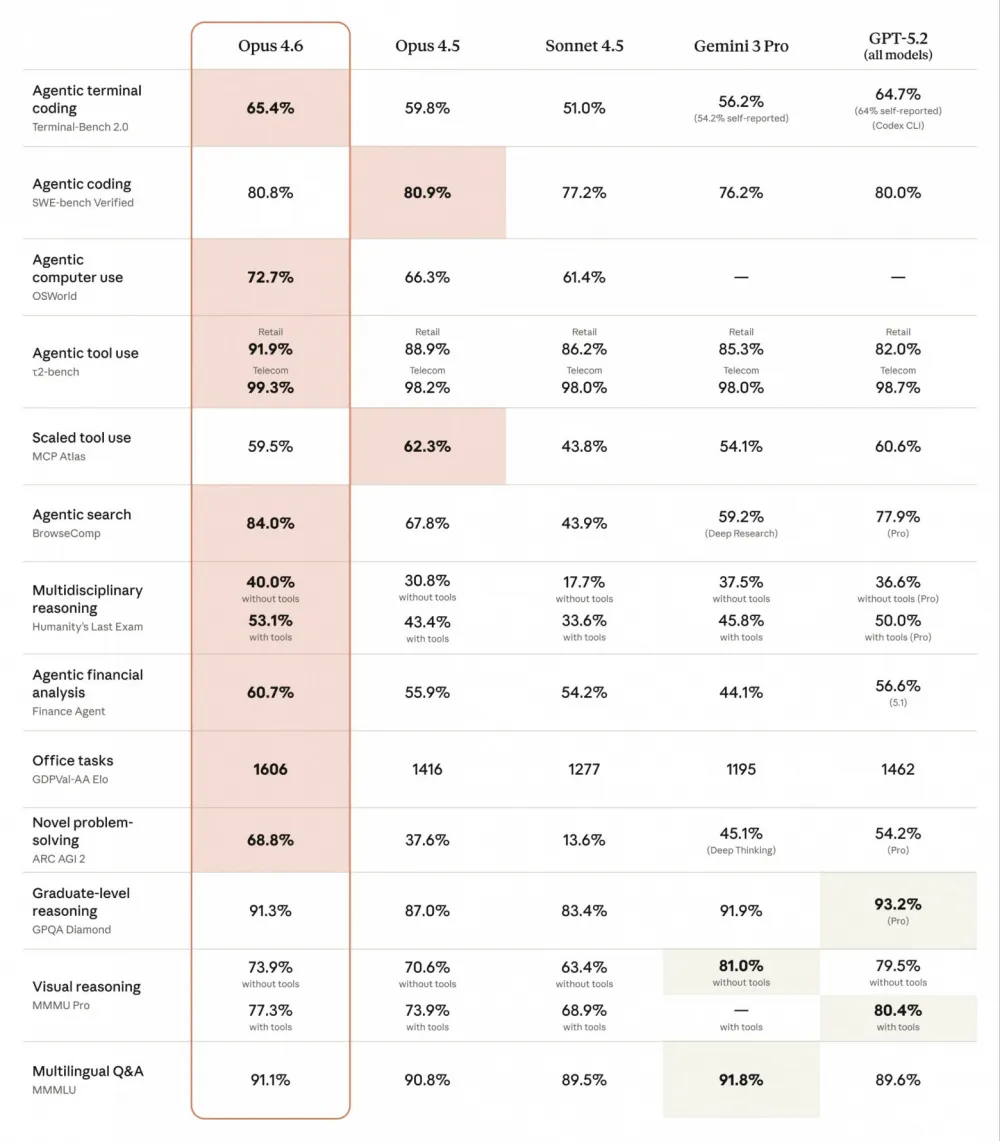
According to Azure AI Foundry and system card, Opus 4.6:
Terminal-Bench 2.0 (agent in terminal): 65.4%
SWE-bench Verified (agent fixing real bugs): 80.8%
OSWorld (computer-user, visual desktop): 72.7%
BrowseComp (agent search across the web): 84.0%
GDPval-AA (office knowledge-work): Elo ≈1600, ahead of GPT-5.2 according to ArtificialAnalysis.
MRCR v2 (long-context reading): about 76% against ~18.5% for Sonnet 4.5 in a huge context:
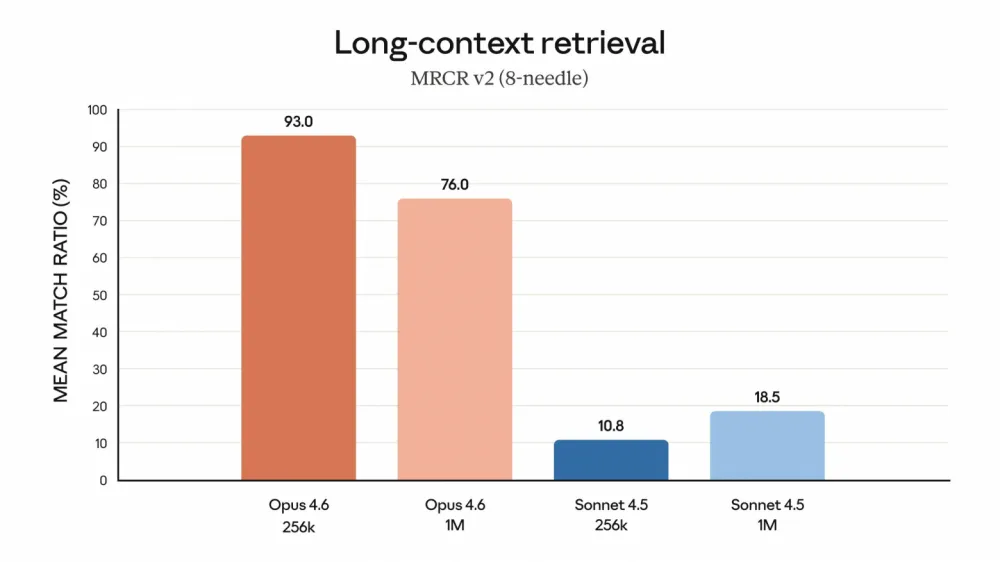
Translating from the language of benchmarks, Opus 4.6 is especially strong where a lot of reading is needed, thinking long, and carefully changing complex systems. In engineering reviews, it is increasingly common to encounter the thought that the code has become noticeably better, but the writing style has become drier compared to Opus 4.5. Therefore, some teams keep Opus 4.5 for documentation and long text, while Opus 4.6 is thrown into coding and complex reasoning.
You have read to the middle of the article, which means that you probably liked the article, as well as my presentation and writing style, so you can support me on my Telegram channel, where a lot of useful and verified information has already been gathered.
8. Security and Failures
From a security perspective, Opus 4.6 shows a lower level of misaligned behavior (deception, flattery, encouragement of misconceptions) and fewer unnecessary failures on normal requests compared to Opus 4.5. However, it is important to understand that this is a comparative result within the Claude lineup, not a comparison with all models on the market.
What's New in GPT-5.3 Codex
GPT-5.3 Codex is a version of GPT-5 optimized for agent coding:
available in the Codex application, CLI, IDE plugins, and in paid ChatGPT
can work with project files, logs, terminal, browser, and GUI
supports vision - can use screenshots of interfaces and files.
I separately covered the Codex application in this post.
In the API documentation, the model is described as a version of GPT-5 for agent coding in Codex with 400k tokens of context, 128k output tokens, and a price of $1.25 / $10 for 1M input/output tokens.
Where Codex Excels:
Can perform a single task for a long time: writing code → running → reading logs → fixing → running again, until achieving the result.
Shows good performance in command line and system scripts: CI/CD, admin scripts, migrations.
In OS-/GUI-agent tasks, uses vision and can click buttons, fill out forms, save files, and navigate between windows.
Benchmarks: where Codex leads
According to the official blog OpenAI, GPT-5.3 Codex shows:
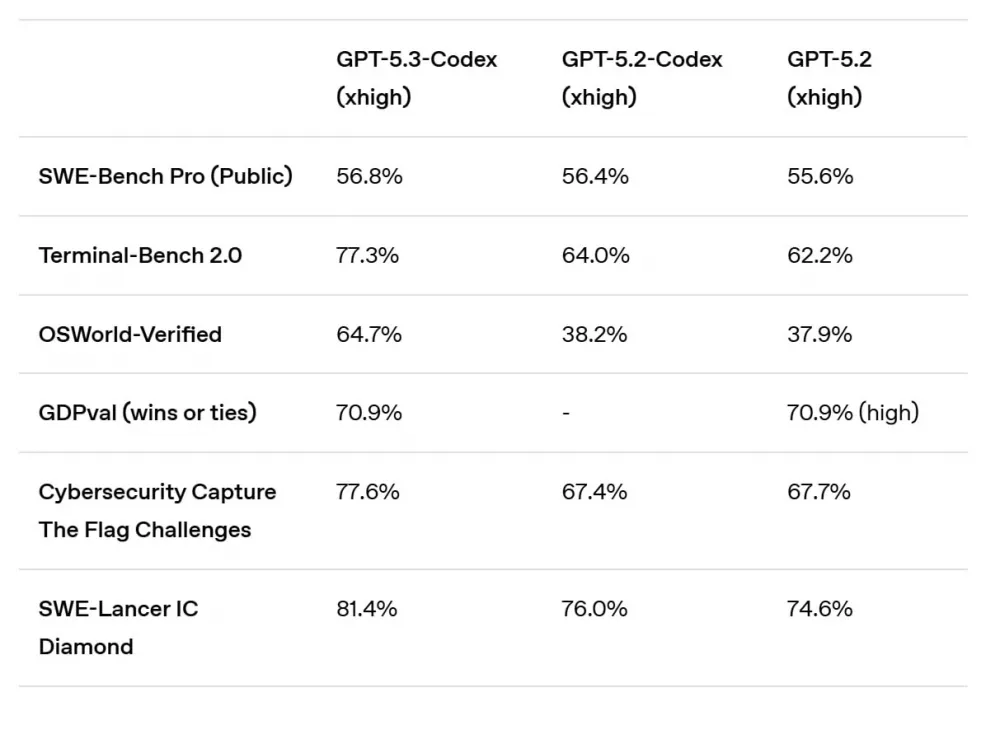
SWE-Bench Pro: 56.8% - a new record for real tasks in 4 languages:
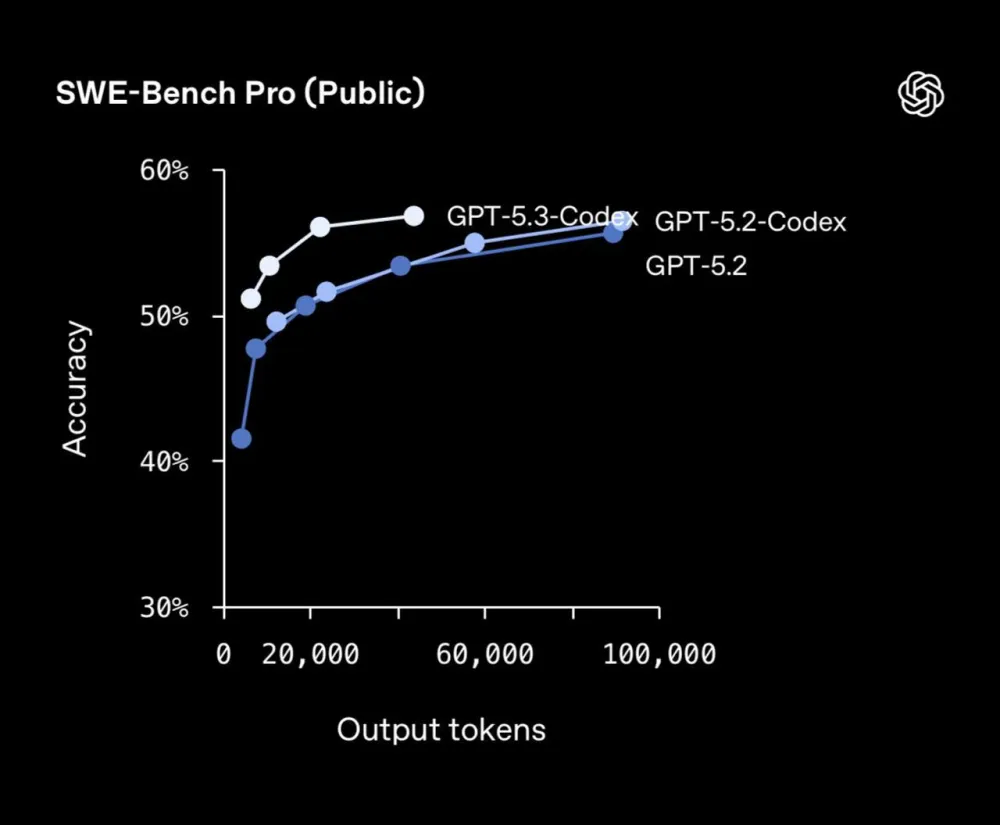
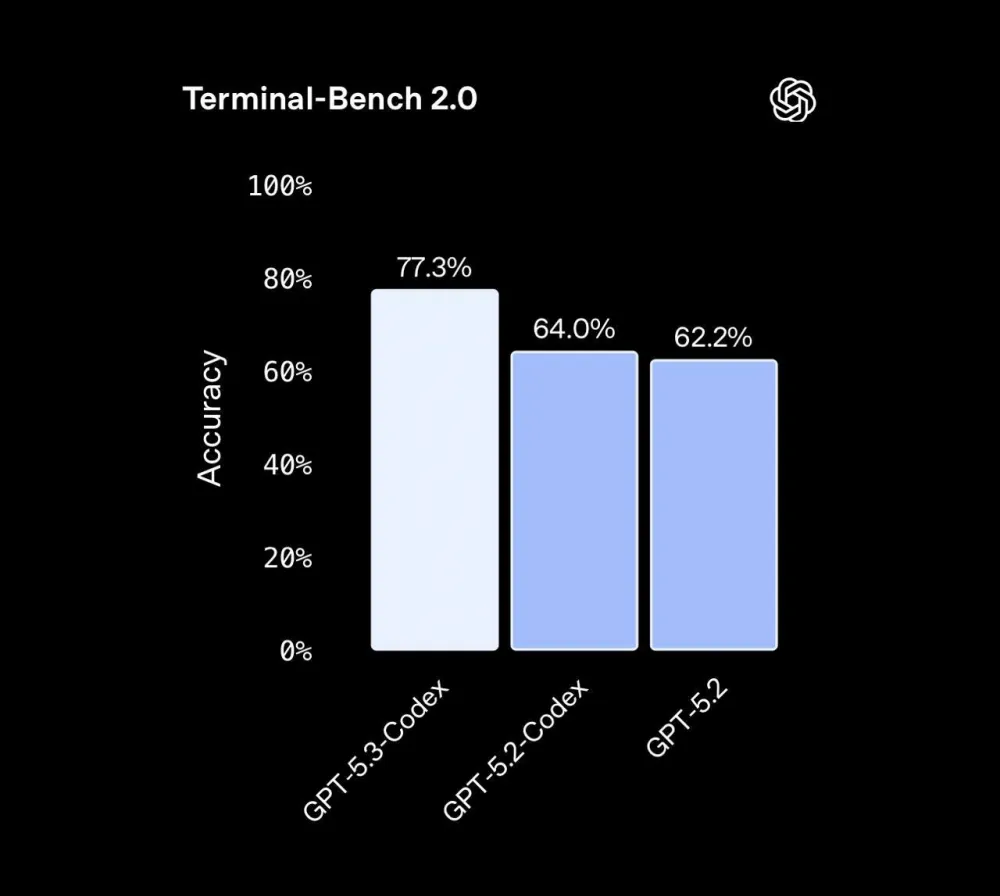
Terminal-Bench 2.0: 77.3% (higher than GPT-5.2-Codex and base GPT-5.2)
OSWorld-Verified: 64.7% (models have to complete tasks in real UI like a human)
GDPval (knowledge work without office constraints): 70.9% wins or draws - level of GPT-5.2, but in agent mode
notable growth in cyber-CTF benchmarks and engineering tasks (SWE-Lancer, security challenges).
Additionally, SiliconANGLE emphasizes that GPT-5.3 Codex is 25% faster than its predecessor in terms of latency in the Codex environment. If interested, here’s my analysis of GPT-5.2 Codex
ChatGPT-5.3 Codex and Claude Opus 4.6: where each excels
We have explored the features and innovations of both models, their benchmarks. And, if we compare Opus 4.6 and GPT-5.3 Codex, we get roughly this picture:
Benchmark / Parameter | Claude Opus 4.6 | GPT-5.3 Codex |
|---|---|---|
Terminal-Bench 2.0 (terminal) | 65.4% | 77.3% |
SWE-bench Verified / Pro | 80.8% (Verified) | 56.8% (Pro) |
OSWorld-Verified | 72.7% | 64.7% |
BrowseComp (search) | 84.0% | no public figure |
GDPval / GDPval-AA | Elo ≈1606 (leaderboard) | 70.9% wins/ties (GDPval) |
Context window | 1M (beta), standard 200k | ~400k |
Max output | 128k | 128k |
Price per 1M tokens | $5 / $25; $10 / $37.5 for 200k+ | $1.25 / $10 |
What conclusions can be drawn?
Terminal-Bench and CLI scenarios: a clear advantage for GPT-5.3 Codex.
Verified benchmarks and long reasoning (SWE-bench Verified, Humanity’s Last Exam, GDPval-AA, MRCR): a stronger point for Opus 4.6.
Computer use (OSWorld): both strong, but Opus has higher figures, while Codex performs well in its own Codex environment with tight integration with tools.
Price: Codex is significantly cheaper in API, Opus is 60–75% more expensive for the same volume of tokens.
In practice, opinions converge: neither model has outperformed the other. They are simply optimized for different task profiles. Opus 4.6 is an engineering architect who reads everything: code, RFCs, business context, thinks, designs, outlines steps and tasks, and keeps in mind the "why" and "how," not just "how." GPT-5.3 Codex is a very fast executor who immediately "jumps into battle": commits, runs, checks logs, feels right at home in the terminal and CI/CD, and will keep working until the tests turn green.
It's more logical to bet on Opus 4.6 when you need very long chains of reasoning and volumes of context (monorepos, large knowledge bases, major legal/financial cases). Where a single brain orchestrator is needed to bring up sub-agents, assign them tasks, and monitor the process. Opus 4.6 excels in mixed tasks (code + research + strategy + legal/business context in one session). And now, office workflows are easier to solve with Opus 4.6 (Excel + PowerPoint).
GPT-5.3 Codex is better when coding prioritizes efficiency, when you already have pipelines with autotests, and the model can be measured by how many tasks it closed before hitting green tests. Also, if you have a lot of OS/GUI automation (frontend autotests, end-to-end scenarios with browsers, CI/CD setup, monitoring, log operations). And you generally need an agent that lives within real infrastructure (GitHub, CI, monitoring) and can find and wisely use available skills/tools without needing to manually write and ask "is there a skill for this task."
Where both models excel: GPT-5.3 Codex and Claude Opus 4.6
There is a zone where both models are good: agent coding on real projects, computer-use and OS agents, knowledge-work (GDPval-class).
The difference is what you are betting on: if maximum immersion in context, accuracy of reasoning, and orchestration of many agents is important to you - Opus 4.6 is your choice. If high speed and productivity in an environment where everything is tied to tests, logs, and tools is a priority - then definitely Codex 5.3 is the best solution.
In general, it's optimal for a team not to choose "either this or that," but to distribute roles: Codex as an execution agent for tests and infrastructure, Opus as an architect and coordinator of complex chains. You can support me on my Telegram channel, where I write about things I understand or am trying to figure out, testing useful AI services, tools for the office, business, marketing, and video.









Write comment