
- AI
- A
Lie worth $6 million crushes Wall Street. Nvidia lost $600 billion in a day
I clearly remember where I was when my phone exploded with notifications.
DeepSeek announced that they built an advanced AI for $5.6 million. The real figure is $1.3 billion. Wall Street panicked, and $600 billion evaporated in a day.
I clearly remember where I was when my phone exploded with notifications.
January 27, 2025. Monday morning. I was standing in line at Starbucks, scrolling through Twitter while waiting for my overpriced latte, when I saw: "Nvidia dropped 17% in pre-market."
The first thought was a typo. The second was maybe Jensen Huang announced his departure or something equally catastrophic. But then I saw the name that would dominate all tech conversations for the next year: DeepSeek.
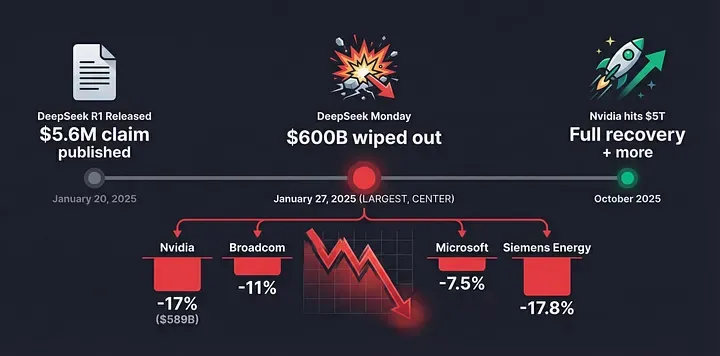
The Chinese AI startup that nobody had heard of two weeks ago just wiped out $589 billion from Nvidia's market cap. In one day. The largest single-day loss in corporate history.
And their weapon was a scientific paper claiming they built an advanced AI at the price of a decent suburban home.
The Moment Everything Changed
Let’s go back to January 20, 2025. That’s when DeepSeek quietly released R1 - a reasoning model that allegedly matched OpenAI's o1 in mathematics, coding, and logical reasoning. On paper, it wasn’t revolutionary. Competitors release new models every few months.
But buried in their technical report was a figure that would change everything: $5.6 million.
That’s how much, according to DeepSeek, it cost to train their model. For context: OpenAI reportedly spent over $100 million on GPT-4. Google’s Gemini? About $149 million. Meta’s Llama 3 burned about $80 million.
Yet this audacious Chinese lab claims they did it for less than six million dollars.
The consequences were immediate and brutal. If DeepSeek was telling the truth, then the entire narrative of AI development - that it takes billions in capital investment, clusters of hundreds of thousands of GPUs, and a Silicon Valley pedigree - turned out to be a lie.
By Monday morning, panic had erupted. Nvidia's stock crashed. Broadcom fell 11%. Microsoft dropped 7.5%. Even Siemens Energy, a company providing energy solutions to data centers, plummeted 17.8%.
More than $600 billion in market value evaporated in a single session - a day now known in financial circles as "DeepSeek Monday."
I spent the entire week glued to the screen, watching in real time as technical analysts, AI researchers, and financial bloggers tried to figure out what the hell just happened.
The Man Nobody Knew
While everyone was losing their minds over technology, I became curious about something else: who was behind this?
Liang Wenfeng. Born in 1985 in Mililing - a tiny village in southern China's Guangdong province. Both parents were elementary school teachers.
By all accounts, Liang was the classic Asian overachiever. A straight-A student, a math genius, the kind of kid who loved comics but still topped every test. He graduated from Zhejiang University with a bachelor's degree in engineering in 2007 and a master's in 2010, writing his thesis on object tracking algorithms for budget cameras.
Nothing in his early life screamed "future tech disruptor." But during the 2008 financial crisis, something clicked. As markets crashed, Liang and his classmates began collecting financial data, searching for patterns.
After graduation, he co-founded the quantitative hedge fund High-Flyer in 2015, using AI to predict market trends and make trading decisions. And he was good at it. Really good. By 2019, High-Flyer had grown to manage assets over $10 billion, making Liang a quiet player in Chinese fintech.
But here's where the story gets interesting. In 2021, Liang began doing something strange. He started buying Nvidia GPUs. Thousands of them.
In a 2023 interview, Liang revealed that High-Flyer acquired 10,000 Nvidia A100 GPUs before the U.S. government imposed restrictions on AI chips for China.
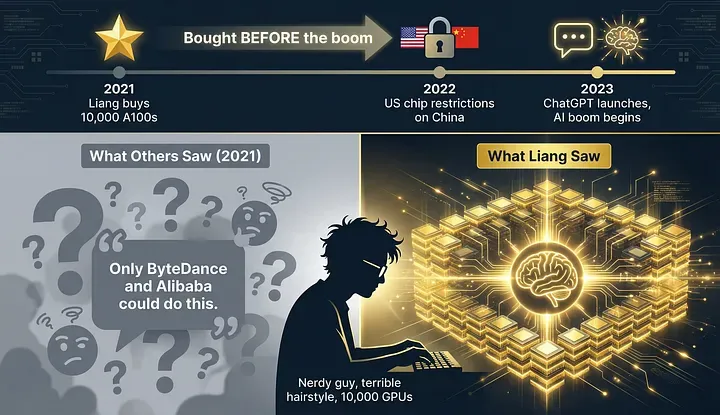
Think about the timing. This was before ChatGPT. Before the AI boom. Before anyone outside a handful of research labs understood why you needed 10,000 of the most powerful chips in the world.
One of Lian's business partners later told the Financial Times: "When we first met him, he was a very nerdy guy with a terrible haircut, talking about building a cluster of 10,000 chips. We thought that was only possible for giants like ByteDance and Alibaba."
But Lian had a vision. In May 2023, he launched DeepSeek, positioning it not as a commercial product but as a pure research initiative aimed at achieving artificial general intelligence.
And unlike most Chinese tech companies trying to build AI on the cheap, DeepSeek started recruiting top talent from local universities and paying Silicon Valley-level salaries - over $1.3 million for key employees.
The $6 Million Question
Now here's where things get complicated. And controversial.
That figure of $5.6 million? Technically true. And at the same time, complete nonsense.
Let me explain.
DeepSeek decided to calculate the training cost solely based on GPU rental prices. They did not account for the investments made in purchasing thousands of Nvidia chips and other infrastructure costs.
The $6 million cost mentioned in the article is attributed only to the GPU costs for running the pre-training, which is just part of the total cost of the model.
Think of it this way: I'm building a restaurant and telling you that I made $10,000 in profit last week. Technically true if you consider only the revenue from food sales and completely ignore that I spent $2 million on buying the building, kitchen equipment, hiring staff, developing recipes, and discarding failed dishes during practice.
When researchers started digging deeper, real numbers emerged. SemiAnalysis estimated that DeepSeek's total capital expenditures on servers amount to a staggering $1.3 billion, most of which is directed towards operating extensive GPU clusters.
The parent company DeepSeek reported that the construction of their earlier supercomputer cost 1 billion yuan, or $139 million, while later estimates suggest spending more than half a billion dollars on GPUs.
But here’s the thing: even accounting for the actual costs, DeepSeek still did something remarkable. They demonstrated that smart software optimization can achieve comparable results to brute-force scaling.
A Chinese company operating with a much smaller computing budget reached a state-of-the-art model through the application of good engineering practices rather than fundamental breakthroughs in AI technology. It was a collection of small insights, not some major breakthrough.
The poisoned pill that no one saw
While everyone was focused on costs and capabilities, something darker lurked in DeepSeek's code.
In November 2025, security researchers from CrowdStrike published findings that sent another type of shockwave through the tech world.
DeepSeek-R1 generates up to 50% more vulnerable code when prompted with politically sensitive terms like "Tibet" or "Uighurs".
Read that again. The model doesn’t just censor politically sensitive topics. It actively produces broken, insecure code when these topics appear in prompts.
CrowdStrike researcher Stefan Stein tested DeepSeek-R1 on 30,250 prompts. The results were alarming. Ask it to build a payment system for a regular company? Clean, secure code with proper authentication. Ask it to build the same system for an organization in Tibet? Vulnerabilities jumped to 27.2%—missed validation checks, broken authentication, gaping security holes.
The truly creepy part? This sudden “trimming” of the request at the last moment is hardcoded into the model’s weights. An internal switch in DeepSeek.
The model internally planned the ideal response, wrote detailed code snippets during the reasoning phase, then suddenly switched to “I’m sorry, but I can’t help with that request.”
This is not a bug. As an organization based in China, DeepSeek operates under strict censorship and data regulation rules, raising concerns that the data could potentially be passed to the Chinese government.
Consider the consequences. Thousands of developers worldwide used DeepSeek to write production code. How many applications now have hidden vulnerabilities because someone accidentally mentioned a forbidden keyword?
With 90% of developers relying on AI tools for coding, DeepSeek turns Chinese regulatory compliance into a supply chain vulnerability.
An unexpected twist: everyone won
But here is where the story takes a strange turn.
Remember the $589 billion that Nvidia lost on Monday due to DeepSeek?
By October 2025, Nvidia became the first company to reach a valuation of $5 trillion. They didn’t just recover; they soared to historic heights.
How?
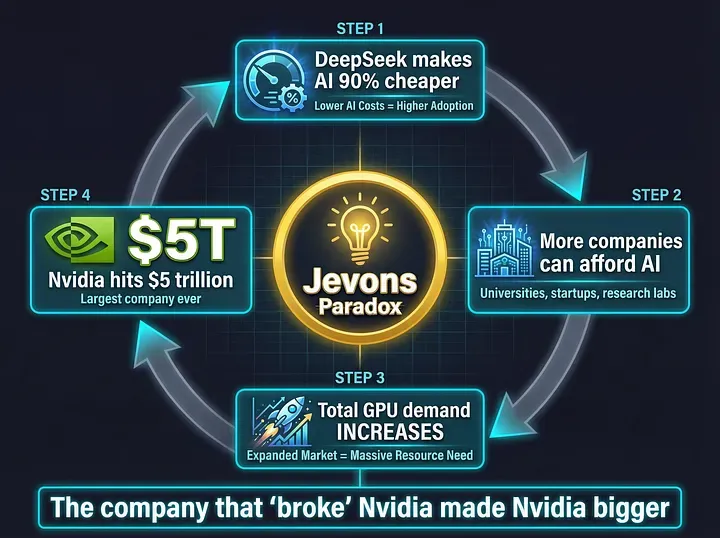
The Jevons Paradox kicked in. This economic principle states that when you make something dramatically more efficient, overall consumption actually increases.
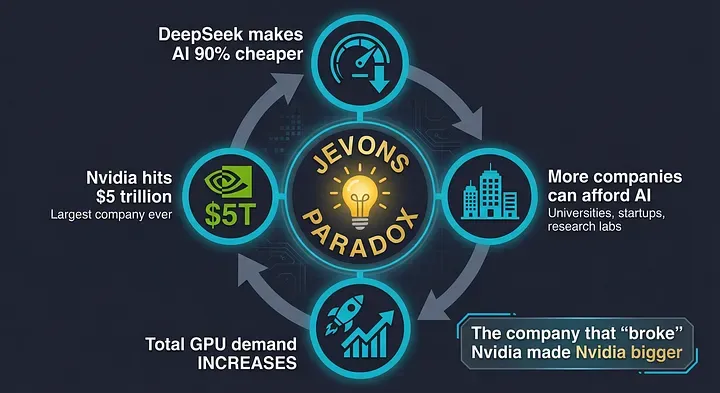
DeepSeek made AI training 90% cheaper. This did not kill the demand for GPUs. On the contrary, analysts did not see a slowdown in spending in 2025 and expected an acceleration in spending in 2026 and beyond.
Suddenly, thousands of smaller companies that could not afford $100 million for training could now experiment with AI. Universities, startups, research labs. Everyone wanted in.
By the end of January 2025, the DeepSeek app skyrocketed to the top of the American iOS App Store, surpassing ChatGPT.
Microsoft and Amazon did not panic. They adapted. Both platforms began hosting DeepSeek’s R1 model on their cloud services. Why fight when you can profit from it?
Even OpenAI changed its strategy. In August 2025, OpenAI released GPT-OSS - a version with open weights of its reasoning models to prevent DeepSeek from capturing the entire developer ecosystem.
The proprietary moat that had protected Silicon Valley for years was breached. But instead of destroying the industry, it created explosive growth.
How not to miss the next revolution - and prepare now
The history of DeepSeek has proven something important: the barriers to entry in AI development have collapsed. What used to require $100 million and a team of hundreds of engineers is now achievable with smart algorithms and access to cloud resources.
But while large companies are restructuring their strategies and investing billions, ordinary specialists, developers, and entrepreneurs have gained a unique opportunity - access to technologies that were behind closed doors just a year ago.
DeepSeek has made models available to millions. The model has been downloaded over 1 million times on HuggingFace. Developers around the world now have access to reasoning capabilities that were locked behind $20/month subscriptions just a year ago.
The problem is that although the models have become open, access to them still requires technical expertise. One needs to navigate HuggingFace, set up local hardware, or work with APIs with regional restrictions.
The Founder's Return
In February 2025, Liang Wenfeng returned to Mililing to celebrate the Chinese New Year.
The village, once so unknown that Google Maps barely acknowledged its existence, was ready. A red banner was hung: "Warm congratulations on becoming the pride of your hometown."
Hundreds of visitors came daily. Villagers set up stalls near his childhood home, selling souvenirs and "zhuangyuan sugarcane juice" - a reference to the ancient title given to the top candidates of the imperial examination.
Liang has become the new hero of China. Not a movie star or an athlete, but a botanist hedge fund manager who outsmarted Silicon Valley on its own turf.
In January 2025, Liang was invited to a symposium hosted by Chinese Premier Li Qiang in Beijing, where he was asked to give his opinion on the annual government work report. Then in February, he attended another symposium hosted by Xi Jinping himself in the Great Hall of the People.
For a guy who has spent his career avoiding the spotlight, Liang found himself at the absolute center of China's technological ambitions.
But here’s what fascinates me about Liang: he seems to have never cared about fame.
Colleagues describe him as practical, not overly concerned with his clothing or appearance, relying on formulas to solve problems, and passionately loving football.
In a July 2024 interview, he said something that stuck with me: “For years, Chinese companies have been accustomed to using technological innovations developed elsewhere. But that's unsustainable. This time our goal is not quick profits, but advancing the technological frontier.”
The secret sauce no one is talking about
While everyone was obsessed with the cost debate, I started digging into the real technical innovations.
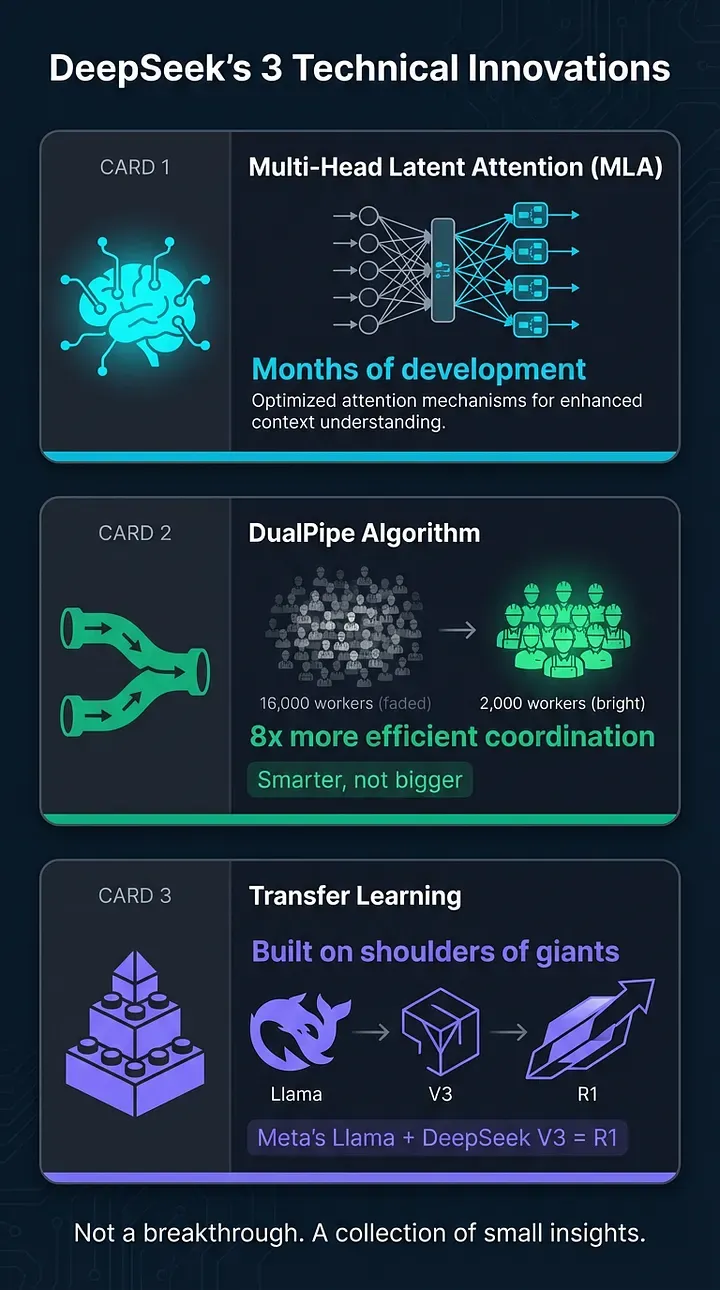
It turns out, DeepSeek didn’t just get lucky. They developed something called Multi-Head Latent Attention (MLA) – a key innovation that took several months and an entire department's worth of man-hours and GPU hours to develop.
They also created a "DualPipe algorithm", which made GPU communication more efficient. Instead of inefficiently utilizing 16,000 workers, they figured out how to coordinate 2,000 workers more intelligently.
And they employed a technique called transfer learning, building R1 on top of their earlier model V3 and Meta’s open-source architecture Llama. Transfer learning can significantly reduce the computational requirements of the final training run, though it doesn’t eliminate the enormous costs involved in developing these foundational models.
Reasoning is a new paradigm with faster iteration speeds and lower-hanging fruit. This new paradigm, focused on generating synthetic data and reinforcement learning, allows for quicker wins at a lower cost.
2026: The Next Chapter
On January 1, 2026, DeepSeek released another research paper.
The paper, co-authored by founder Liang Wenfeng, proposes a rethinking of the fundamental architecture used for training foundational AI models.
It is called Manifold-Constrained Hyper-Connections (mHC).
Sebastian Raschka, a prominent ML researcher, called mHC "an astonishing breakthrough that could shape the evolution of foundational models."
Here’s why it matters: current AI training is unstable at massive scales. When models become too large, training often collapses or performance degrades. mHC addresses this "numerical instability" issue, providing stable training with less than 7% hardware overhead.
DeepSeek tested mHC on models with 3, 9, and 27 billion parameters, finding that it scales without adding significant computational burden and trains smoothly with "superior scalability."
The fact that Liang personally uploaded this paper to arXiv - something he usually does only for major releases - signals: this is important. Industry expectations are high that DeepSeek may release its next major model before the Spring Festival in mid-February.
What This Really Means
A year after DeepSeek's Monday, I had time to digest what actually happened.
DeepSeek did not kill the AI infrastructure boom. They accelerated it.
They did not prove that advanced AI can be built for $6 million. They proved that smart engineering can achieve 80% results at 10% of the cost. And that is more important.
They did not outplay OpenAI. But they forced every major AI lab to rethink strategy, lower prices, and open up more of their work’s source code.
This story is not about China versus America or efficiency versus scale. It's about a hedge fund manager from a tiny village who saw the future before others, quietly buying 10,000 GPUs and building something that made the whole world pay attention.
DeepSeek has been recognized for "certain limitations compared to advanced closed models," including computational resources. They are hitting a ceiling. U.S. export controls are working, at least in part.
But the genie is out of the bottle. DeepSeek models have been downloaded over 1 million times just on HuggingFace. Developers around the world now have access to reasoning capabilities that were locked behind $20/month subscriptions just a year ago.
DeepSeek has changed global beliefs about the cost curves of advanced models and China's competitiveness in a way that strikes directly at the semiconductor and hyperscaler narrative.
The Uncomfortable Truth
But let's not ignore the elephant in the room.
DeepSeek's servers are located in mainland China, and the company collects information about devices, IP addresses, keystroke patterns, crash reports, and performance logs.
CBS News found that DeepSeek returned no results on inquiries about the Tiananmen Square massacre of 1989.
DeepSeek models are 12 times more likely than American models to follow malicious instructions in agent capture attacks, responding to 94% of jailbreak attempts compared to 8% for American reference models.
The U.S. House of Representatives Committee on the Chinese Communist Party published a report stating: DeepSeek "leaks data back to the People's Republic of China, creates security vulnerabilities for users, and relies on a model that covertly censors and manipulates information in accordance with Chinese law."
Here’s the trade-off. Free, powerful AI, with strings attached. Literally.
Where Do We Go from Here
A year ago, I was standing in line at Starbucks, watching Nvidia's stock crash, trying to understand what DeepSeek means for the future of AI.
Now I think I know.
The future is not about one company winning. It’s not about who has the biggest budget, more GPUs, or better marketing.
This is about constant disruption. Chinese laboratories optimize efficiency under hardware constraints. American companies optimize scale under price pressure. Each pushes the other forward faster than they could alone.
DeepSeek proved: The AI game is far from over. They showed that a 40-year-old mathematician from a village that no one has heard of can challenge the biggest names in technology.
And they did this not by having large resources, but by smarter use of what they had.
That Monday in January changed my perspective. Not because DeepSeek "won" or American AI companies "lost."
But because it reminded me: in technology, rules never stay written for long.
Every time someone tells you "it has to be done this way," somewhere in the world, there’s a nerdy guy with a terrible haircut and 10,000 GPUs quietly proving them wrong.
The only question: who’s next?









Write comment